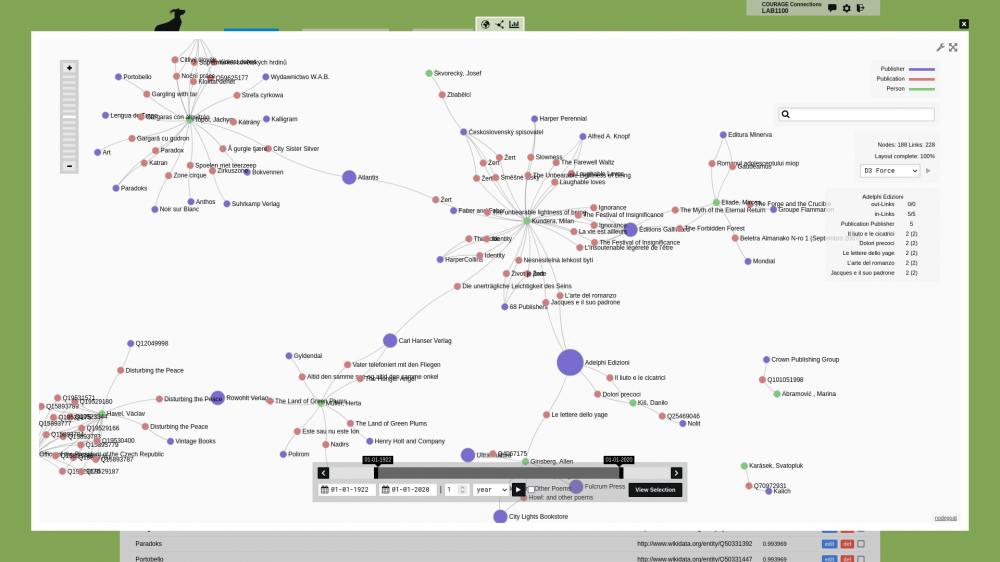
Temporally-aware dynamic network analysis: traversing nodegoat graphs
CORE AdminDuring the conference 'Graphs and Networks in the fourth dimension – time and temporality as categories of connectedness', jointly organised by the Historical Network Research community and Graphs & Networks in the Humanities, we presented a new nodegoat feature: 'temporally-aware dynamic network analysis'. This new functionality extends the Scope and Chronology Statements.
The Scope functionality is used throughout nodegoat to traverse your data model and select elements to be included in a visualisation, analysis, or export. With the Scope, you can limit or expand your data selection. In a prosopographical analyses you might want to include all educational institutes related to one person, plus all the relations of these institutes, while omitting all other personal relations of a person. Follow this Guide to learn how to configure a Scope.
Chronology Statements that you make in nodegoat allow you to specify what you mean by a statement like 'circa'. Instead of using qualitative statements about vagueness, Chronology Statements provide you with a way of making quantitative statements about vagueness. Chronology Statements also allow you to make relational date statements: 'the date point is between the sending of letter X and the sending of letter Y'. Follow this Guide to learn how to store uncertain dates by using Chronology Statements and follow this Guide to learn how to store relational dates by using Chronology Statements.
The temporally-aware dynamic network analysis functionality makes the temporal options offered by the Chronology Statements available on any level of a Scope. This allows you to apply and pass temporality to time-bound connections in any of a Scope's paths. The dates from Chronology Statements can be sourced from every step in the traversal: ascendant or descendant nodes, and combinations. Selected configurations can be applied on any/all of the connections/edges: outbound or inbound directionality, and combinations.
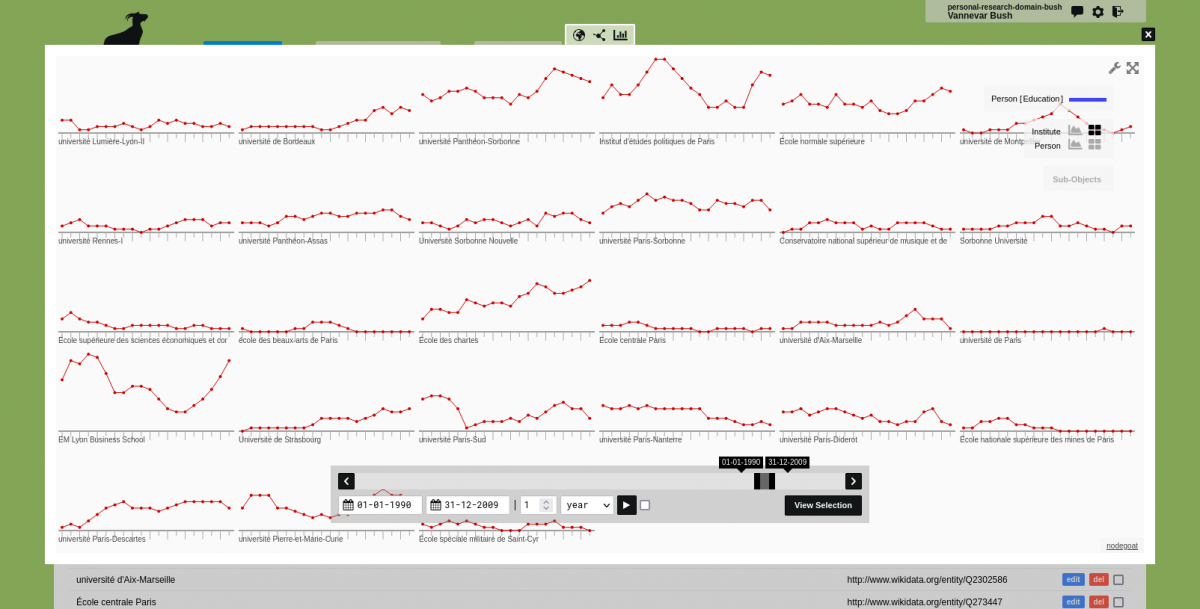
Example: Academic Connections
With this functionality it is now possible to dynamically generate networks of people who attended the same educational institute at the same time, without specifying any dates in a filter. The temporally-aware dynamic network analysis functionality applies the initial date on every other relationship that appears on a specified path:
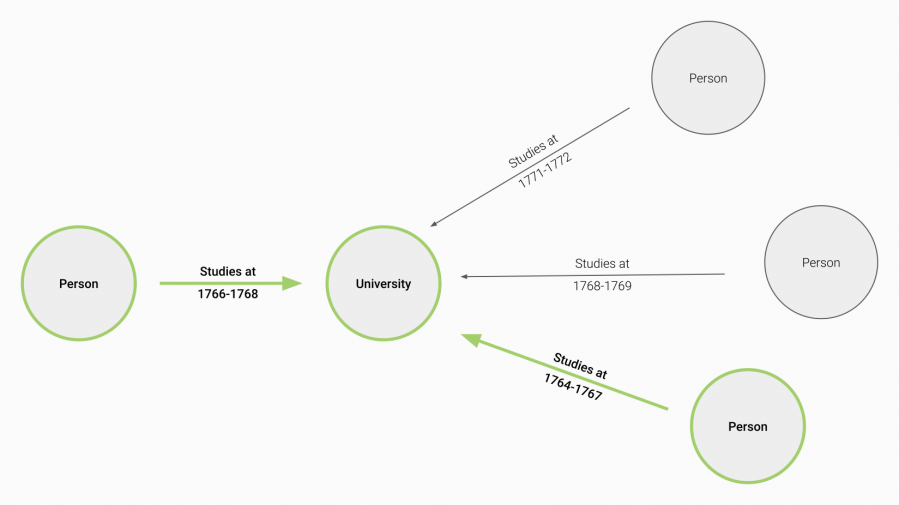
The obvious benefit of this approach is the scalability of this functionality, as it allows you to quickly scrutinise complex networks based on time-bound connections:[....]