How to store uncertain data in nodegoat: incomplete source material
CORE AdminThis blog post is part of a series on storing uncertain data in nodegoat: 'How to store uncertain data in nodegoat', 'Incomplete source material', 'Conflicting information', 'Ambiguous identities'.
You are often confronted with omissions or with inconclusive statements when you deal with historical source material. To let your dataset reflect the nature of your sources, it is important that you include these vague or uncertain statements in your data. This blog post will go over a number of strategies that will help you to deal with these cases in your nodegoat project.
A common scenario is a case where you lack information. When this happens, you can decide to leave a given description, date, or location empty. This gives you the ability to create a filter that finds the objects that have empty descriptions, dates, or locations.
In another situation you might encounter a source that is partially lacking. The source does provide you with some information, but is inconclusive about the certainty of the information. An example of this is the entry on John Chamberlayne in the Dictionary of National Biography:

The first sentence of his entry reads: "CHAMBERLAYNE, JOHN (1666–1723), miscellaneous writer, a younger son of Edward Chamberlayne [q. v.], was born about 1666, probably in or near London."
We will discuss four strategies for accommodating this uncertain source: a true/false statement on certainty, a scale on the level of certainty, entering chronology statements, and entering geometries.
These strategies will be put to use in the data model that has been created in the nodegoat guide 'Create your first Type'. If you haven't set up a data model in your nodegoat environment yet, you can follow this guide to do so. If you already have a data model, you can apply the strategies discussed below in your own data model.
Uncertain: True
A straightforward way to deal with incomplete data points is to flag them out as such. This can be achieved by adding additional remarks to your statements in the form of Object Descriptions or Sub-Object Descriptions. To do so, you have to adapt your data model. Go to Model, then go to 'Types' and edit the type 'Person'. Switch to the tab 'Sub-Object', find the the Sub-Object 'Birth' and go to the tab 'Descriptions'. Enter 'Location Uncertain' into the input field to provide this Sub-Object Description with a label. Use the dropdown menu to change the value type from 'String' to 'True/False'. The Sub-Object should now look like this:

Click 'Save Type'. Go to the Data section of your environment and go to the Type 'Person'. Click 'Add Person'. When you now enter John Chamberlayne, you are able to specify that the location of this birth is uncertain. To do so, scroll down to the Sub-Objects Editor and click on the plus icon next to ‘Birth'. The default value of the Sub-Object Description 'Location Uncertain' is 'None'. To make an explicit statement that this location is uncertain, change the value from 'None' to 'Yes'.

The fact that the location of his birth is uncertain is now included in your dataset. You can add such a statement anywhere in your data model. For the Sub-Object 'Birth', a 'True/False' Sub-Object Description called 'Date Uncertain' might be a valuable addition as well. 'Location Uncertain' and 'Date Uncertain' are also statements that could be added for the Sub-Objects 'Death' and 'Place of Residence'. On the level of the Object Descriptions, you could add a statement like 'Family Name Uncertain' and set this to 'True/False'.
These statements are a reflection of the source material that is currently available to you. Whenever more information becomes available, you can update the data and change 'Location Uncertain' from 'Yes' to 'No'.
Now that you have stored the fact that a statement is uncertain, you can create filters to find data that you are certain about. You can also decide to make a filter to find all the data that you are uncertain about, so know which objects still need attention. Follow the 'Create a Filter' guide to learn how to make these filters.
When you visualise your data, you can first make a filter to filter out all the data that you are uncertain about. This allows you to only create data visualisations of certain data. You can also use the conditional formatting options to give your uncertain data a different colour.
A 'True/False' statement for uncertainty is a basic approach to deal with the consequences of vague data. It is easy to handle and is quite insensitive to errors, as you only have two options: something is either uncertain or it is not. On the other hand, it does not allow for much differentiation. To allow for a greater range of inspecificity you can start to classify the levels of uncertainty.
Certainty: Very Uncertain
You can classify levels of uncertainty in nodegoat by creating a new Classification. After you have entered a number of categories in this Classification (e.g. 'uncertain', 'very uncertain', etc.), you can assign these categories to objects in your environment.
Start by creating a new Classification. Go to 'Model' and switch to the tab 'Classifications'. Click 'Add Classification'. Give this classification a name like 'Certainty' and click 'Save Classification'. Go to Management and Projects and edit your project to enable this newly created Classification in your project. Read more about this process in the guide 'Add a Classification'.
To enter categories in this Classification, go to the Data section of your environment and switch to the tab 'Classifications'. Open the newly created Classification 'Certainty' and click 'Add Certainty' to specify categories. You could work with a scale like this: 'Very Certain, Certain, Uncertain, Very Uncertain'.

You can use these categories anywhere in your data model. This allows you to classify the certainty of every statement that you make. As an example, you can enable this for the location of the birth of a person. To do so, go to Model, then go to 'Types' and edit the type 'Person'. Switch to the tab 'Sub-Object', find the the Sub-Object 'Birth' and go to the tab 'Descriptions'. Add a Sub-Object Description with the name 'Certainty of Location' and change the value type from 'String' to 'Reference: Classification'. Select the Classification 'Certainty' from the dropdown menu.

Click 'Save Type'. Go to the Data section of your environment and go to the Type 'Person'. Click 'Add Person'. When you now enter John Chamberlayne, you are able to specify how certain the location of his birth is. To do so, scroll down to the Sub-Objects Editor and click on the plus icon next to ‘Birth'. Click on the input field with the magnifying glass to see the list of categories that have been stored in the Classification 'Certainty'. Select the category 'Uncertain' to express your level of certainty regarding the location of his birth.
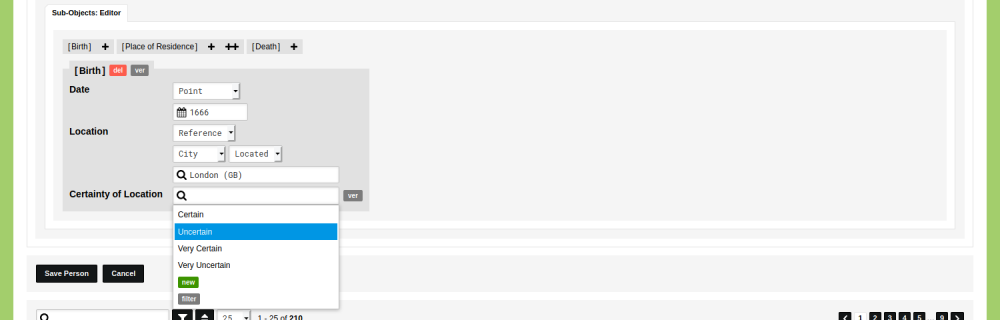
As noted above, you can add a statement like this anywhere in your data model. These statements will allow you to be clear about the certainty of the data you store. You can use these expressions in your own research process to find and edit the data that you are uncertain about, or create filters that filter out any uncertain data. These statements can also be used to make your assessment of the sources explicit to your peers.
To add more transparency about your decisions, you can add additional Classifications to express how you assessed the certainty of your data. You could create a Classification with the name 'Derived from' in which you identify categories like 'Primary Sources', 'Secondary Sources', 'Inference', and 'Conjecture'. Adding these statements to your data allows you to be clear about the manner in which the data was created.
Whenever you add or edit data in nodegoat, you can click the grey 'ver' button to inspect the version history of an element and to add Source References. Use the Source References to specify the source material that you used for the data that was classified with the categories 'Primary Sources' or 'Secondary Sources'. Follow the guide 'Add Source References' to learn more about adding Source References.
You can also create a granular uncertainty classification by using a numerical scale. To do this, edit your data model and add a new Object Description with the value type 'Integer'. You can opt for a 1-10 scale, or a 1-100 scale to allow for more granularity. A scale like this allows you to make a filter that reads as 'show me all the books of which the author has been assigned with a certainty of at least 80'. When you publish your data, a clear description behind the rationale of the scale should be included.
Chronology Statements
While vague or uncertain dates can be classified as such by means of the process described above, nodegoat also has a functionality that allows you to explicitly describe the level of uncertainty for each date. You do this by creating 'Chronology Statements'.
You can use Chronology Statements to store a date of birth as: 'the date point is between 2 years before the begin of 1666 and 2 years after the end of 1666'. Follow the guide 'Storing Chronology Statements' to learn how to do this.
You can also use Chronology Statements to store the date of a letter as: 'letter X was sent 3 months after letter Y was received'. Follow the guide 'Storing Relational Chronology Statements' to learn how to do this.
In the case of John Chamberlayne, the source states that he was born 'around 1666'. From a historical perspective, this statement makes sense: we know that it happened around the year of 1666, we just do not know in which year exactly. But as soon as we try to interpret this statement, we run into a challenge: although we know that the date is uncertain, we cannot assess how uncertain it is. Did the author mean 'either 1665 or 1666', or do we need to take a range from 1656 until 1676 into account?
The source notes that he published a book in 1685, so a twenty year range seems unlikely. To store a range from two years before 1666 until two years after 1666, you would create a new Chronology Statement. Go to the data section of your nodegoat environment and open the Type 'Person'. Click 'Add Person' and scroll down to the Sub-Object Editor. Click on the plus icon next to ‘Birth' to enter a birth date. The default setting for storing a date is a point in time. To enter a Chronology Statement, change the dropdown menu from 'Point' to 'Chronology'. Click the green 'create' button to open the dialogue with which you can specify the Chronology Statement.
In the dialogue that appears you see a dropdown menu that is set to 'Point', an input field, and an option to specify a time range. Change the dropdown menu from 'Point' to 'Between Statements' and enter the statement as shown below:
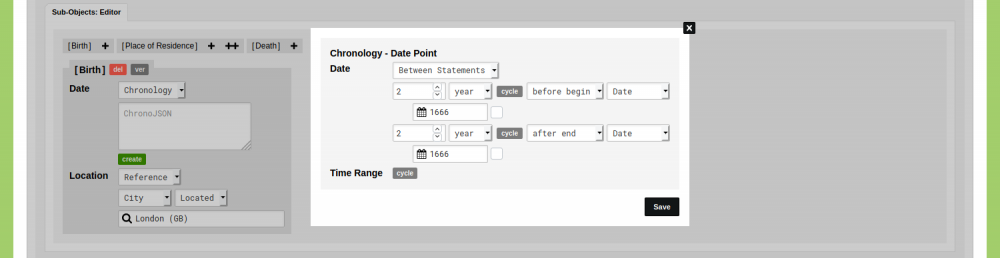
This statement translates to a date point between 2 years before the begin of 1666 and 2 years after the end of 1666. Click 'Save' and click 'Save Object'. When you view this object, you see that this statement has been computed to a date range. This range is used in visualisations, for filtering, and for analysis functionalities in nodegoat.
The added benefit of this approach is that your uncertainty statement is now transparent. Your peers know how uncertain the date is.
Geometries
Locations can be stored in nodegoat together with a statement about the level of certainty of the location. These statements allow you to specify how certain you are about a geographical point. Another approach to storing uncertain spatial data is to step away from points and use areas instead. These areas can be stored in nodegoat in the form of geometrical data, formatted as GeoJSON.
Follow the guide 'Storing Spatial Data' to learn how to store geometries in your nodegoat environment.
In the case of John Chamberlayne, the source states that he was born 'probably in or near London'. This single statement already contains various forms of uncertainty: he was born in or near London, and even this assessment is only a probability. Both uncertainties can be stored in nodegoat.
To state that he was born in or near London, you can work with an area. How 'near London' should be interpreted is an open question of course. You can inspect a map of that time to see how much land was considered to be 'London' at the end of the seventeenth century, for example the map 'London &c. actually surveyed of 1682 by William Morgan'.
To store an area for his birth, go to the data section of your nodegoat environment and open the Type 'Person'. Click 'Add Person' and scroll down to the Sub-Object Editor. Click on the plus icon next to ‘Birth' to enter a birth location. The default setting for storing a location is a location reference. To enter an area, change the dropdown menu from 'Reference' to 'Geometry'. You will see an input field in which you can enter geometrical data in the GeoJSON format. Clicking the green 'create' button will send you to geojson.io, where you can use the polygon option to draw an area that captures the meaning of 'near London in 1666'.
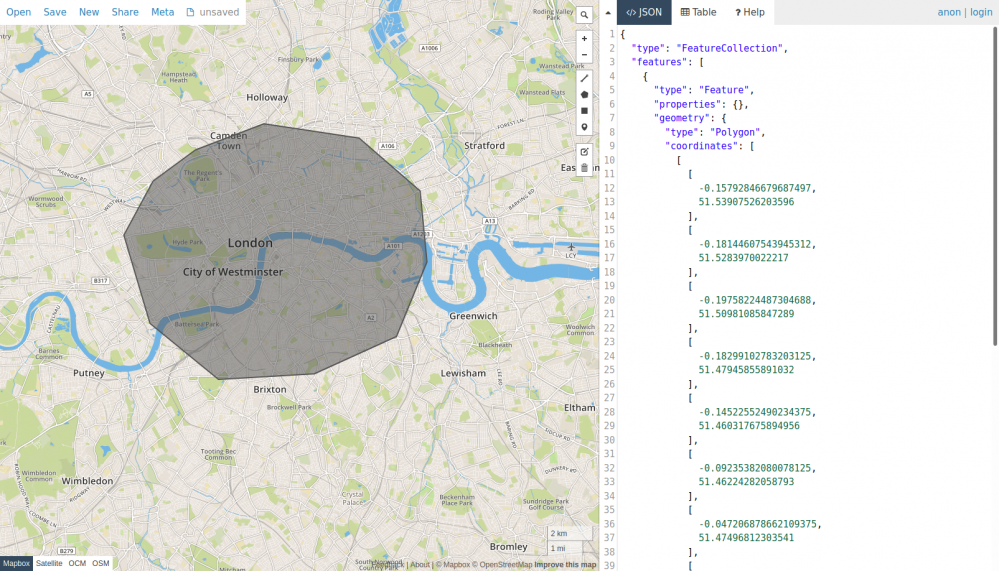
Copy the generated GeoJSON data to your clipboard. Go back to your nodegoat environment and paste the copied GeoJSON data into the input field. Save the object and run the geographic visualisation to inspect this data on a map.
Even though the size of the area is speculative, you have created a geographical statement that captures the wording 'in or near London' as it was used in the source. If you want to account for the word 'Probably', you can use the approach shown above in which you create a Classification for various levels of certainty.
When you want to use a geometry like this more than once (e.g. to map other events also as taking place 'in or near London') you can store these geometries in a new Type. This new Type will host all your geographical statements (e.g. a historical region, or a specific building in a town), and you can link to them by making location references. You can learn how to do this by following the guide 'Create your own Gazetteer'.
Concluding Remarks
These four strategies can be applied to most historical sources. You can choose to combine multiple strategies in your project, or even apply multiple strategies to the same statement.
By explicitly stating the level of uncertainty in your dataset, you are transparent about the nature of the sources and about your interpretation of the vagueness. This allows you to filter out uncertain data, or create visualisations in which you highlight your uncertain data. This transparency is also a great service to your peers, since they will be able to interpret what you mean by 'around 1666'.
Read the other blog posts in this series: 'Conflicting information' and 'Ambiguous identities'.
Tobias Winnerling contributed to this blog post as part of his project 'Charting the process of getting forgotten within the humanities, 18th-20th centuries: a historical network research analysis' (MSCA Action 789672, October 2018-September 2019). Read more about this project on his website fading18-20.hypotheses.org.
Comments
Add Comment