How to store uncertain data in nodegoat: conflicting information
CORE AdminThis blog post is part of a series on storing uncertain data in nodegoat: 'How to store uncertain data in nodegoat', 'Incomplete source material', 'Conflicting information', 'Ambiguous identities'.
When you work your way through your source material, you might encounter two sources that deal with the same subject but contain contradictory data. In these cases, you usually have two options: you either choose one of the sources based on its reliability, or you make an interpretation that combines the data from both sources. To account for disagreement in your sources, a third option is to include both statements in your dataset. This blog post will show you how to include conflicting information in your nodegoat project.
This blog post uses the data model that was created in the nodegoat guide 'Create your first Type'. If you haven't set up a data model in your nodegoat environment yet, you can follow this guide to do so. If you already have a data model, you can apply the steps discussed below in your own data model.
The multiple births of John Chamberlayne
The Dictionary of National Biography of 1887 writes that John Chamberlayne was born 'about 1666'.

In a more recent lemma, in the Oxford Dictionary of National Biography (2009 version), he is said to be born in '1668/9'.
The first source, published in 1887, does not give any details on the way in which the statement 'about 1666' was formulated. The second source, first published in 2004, states that he matriculated from Trinity College, Oxford, on 7 April 1685, aged sixteen. This fact has allowed the author to conclude that he must have been born in either 1668 or 1669. This assumption rests on two premises: that the matriculation record lists an exact age (and not an estimate) and that John Chamberlayne knew the date of his birthday precisely (which in the 17th century was not necessarily the case).
Because it is impossible to assess which source is correct, it is better to store both statements in your database. To do so, you enter two 'Birth' Sub-Objects for one person.
When you go to the Data section of your environment and add a new Object in the Type 'Person', you will see that the Sub-Object 'Birth' can be added only once. This limit is signified by the single plus icon shown next to the name of this Sub-Object. The double plus icon next to the name 'Place of Residence' signifies that this Sub-Object can be entered multiple times.

The limit on the 'Birth' Sub-Object has been set in your data model. When you created the Type 'Person', the 'Birth' Sub-Object was set to have a single occurrence. See the guide 'Create your first Type' to learn more about this.
To be able to add multiple 'Birth' Sub-Objects, you need to change the data model. To do so, go to Model and edit the Type 'Person'. Go to the tab 'Sub-Object' and locate the 'Birth' Sub-Object. Uncheck the 'Single' option, to allow for more than one 'Birth' Sub-Object. If you intend to allow for multiple 'Death' Sub-Objects, you can also uncheck the 'Single' option for this Sub-Object.
Go to the Date section of your environment and select the Type 'Person'. Click 'Add Person' and scroll down to the Sub-Object Editor. Click the plus icon next to ‘Birth' twice to create two Sub-Objects.
Both dates are vague, so you need to make a Chronology Statement for both dates. To do this, change the dropdown menu next to 'Date' from 'Point' to 'Chronology'. Click the green 'create' button to open the dialogue in which you can define your Chronology Statement. To learn how Chronology Statements can be defined, follow the guides 'Storing Chronology Statements' and 'Storing Relational Chronology Statements'.
The first date is 'about 1666'. To account for this, you can define a Chronology Statement that translates to a date point between 2 years before the begin of 1666 and 2 years after the end of 1666.
The second date is '1668/9'. To account for this, you can define a Chronology Statement that translates to a date point between after the begin of 1668 and before the end of 1669.
After you have defined both Chronology Statements, the Sub-Objects will look like this:
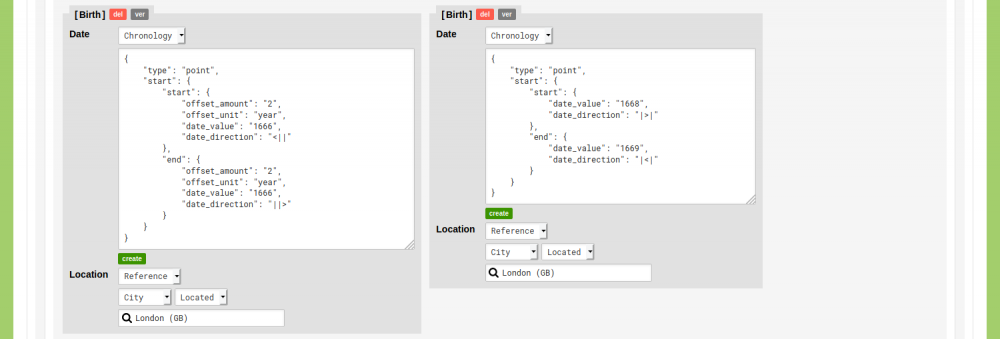
Click the grey ‘ver’ button to open a dialogue in which you can inspect the version history of an element and where you can store Source References. Select the Type in which you have stored your source material. If you have already stored the two publications that contain the statements shown above, you can select them. If you haven't stored these publications yet, you can add them via the green 'new' button. Follow the guide 'Add Source References' to learn more about adding Source References.
Click 'Save Person' to store this Object. Open the Object to view it. You will see both dates of births listed, including an indication of the ranges they represent.
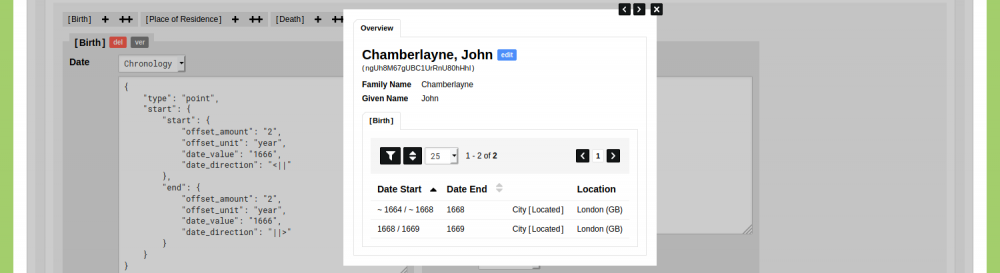
Concluding Remarks
Multiple possibilities for a single statement can occur everywhere in your dataset. To account for a multitude of options, your data model should be able to store multiple values per statement. For Object Descriptions in which you store a name, you can enable the option 'Multiple', so you can store multiple names per person. You can also create additional Object Descriptions to store alternative names, pseudonyms, misspellings, etc.
In laying open the claims you make about the validity and nature of your data, you allow yourself to trace your own reasoning. By including the vagueness and conflicts of your sources in your dataset, you can be very precise about the underlying uncertainty. As always, precision comes at a price, and that is labour. You have to ask yourself which degree of precision is necessary for your purposes, and how to achieve a balance between precision and the required time investment.
Read the other blog posts in this series: 'Incomplete source material' and 'Ambiguous identities'.
Tobias Winnerling contributed to this blog post as part of his project 'Charting the process of getting forgotten within the humanities, 18th-20th centuries: a historical network research analysis' (MSCA Action 789672, October 2018-September 2019). Read more about this project on his website fading18-20.hypotheses.org.
Comments
Add Comment