nodegoat APIs available in the OpenAPI Description
CORE AdminEvery nodegoat API is now described by an OpenAPI Description (OAD). A .yaml file is automatically generated based on the current configuration of any project specific API. This machine-readable document describes all available endpoints for the selected project.
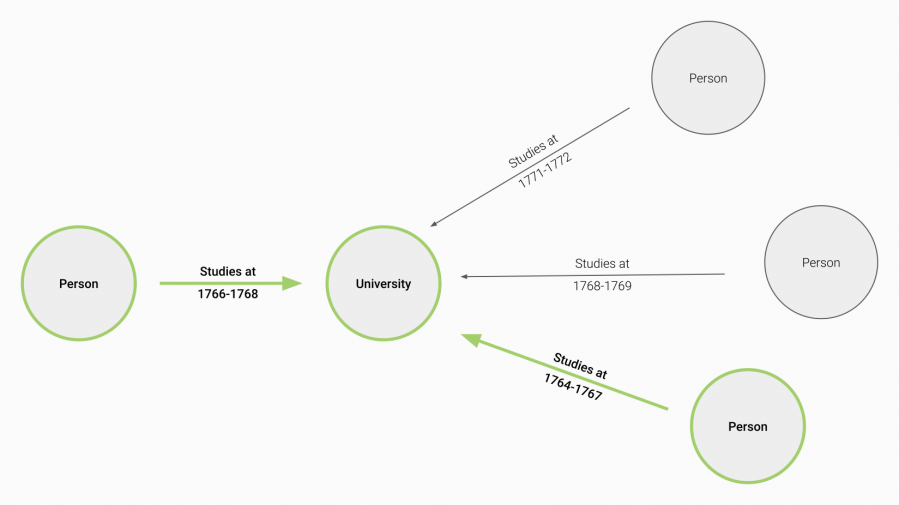
Example of an output, available via https://demo.nodegoat.io/project/1.openapi:
---
openapi: 3.1.1
info:
title: Demo - Correspondence Networks
version: "20251112.154849"
description: API description for Project "Correspondence Networks"
externalDocs:
url: https://documentation.nodegoat.net/API
description: Full documentation for Data API.
servers:
- url: https://demo.nodegoat.io/project/1/
description: ""
paths:
/{id}:
get:
summary: Get Objects based on an identifier.
parameters:
- $ref: '#/components/parameters/data.identifier.path'
responses:
200:
content:
application/json:
schema:
$ref: '#/components/schemas/data.type_objects.json'
application/ld+json:
schema:
$ref: '#/components/schemas/data.type_objects.jsonld'
description: List of one or more Objects that match the given identifier.
/:
get:
summary: Get Objects based on an identifier.
parameters:
- $ref: '#/components/parameters/data.identifier.query'
responses:
200:
content:
application/json:
schema:
$ref: '#/components/schemas/data.type_objects.json'
application/ld+json:
schema:
$ref: '#/components/schemas/data.type_objects.jsonld'
description: List of one or more Objects that match the given identifier.
/data/type/{type_id}/object/:
get:
summary: Get Objects from a Type.
parameters:
- $ref: '#/components/parameters/model.type_id'
- $ref: '#/components/parameters/other.search'
- $ref: '#/components/parameters/other.limit'
- $ref: '#/components/parameters/other.offset'
- $ref: '#/components/parameters/other.filter'
- $ref: '#/components/parameters/other.scope'
- $ref: '#/components/parameters/other.condition'
responses:
200:
content:
application/json:
schema:
$ref: '#/components/schemas/data.type_objects.json'
application/ld+json:
schema:
$ref: '#/components/schemas/data.type_objects.jsonld'
description: List of Objects for the given Type ID and the query parameters.
[...]
Now that this description is in place, the output can be validated by means of the Swagger validator, via https://validator.swagger.io/. Enter 'https://demo.nodegoat.io/project/1.openapi' in the input field to explore the API. nodegoat user without a sub-domain for their research environment can use this modified validator that applies the authentication before the initial request.[....]