Using nodegoat
Hosted nodegoat accounts are freely available for individual research projects.
For collaborative research projects it is possible to run nodegoat on your own server. Go to the nodegoat Products page to learn more about running nodegoat on your server.
About nodegoat
nodegoat is conceptualised and developed by LAB1100. Some frequently asked questions on nodegoat are answered here: nodegoat FAQ. Learn more about using nodegoat by following the Guides, or by exploring the Documentation.
Methodology
nodegoat allows scholars to build datasets based on their own data model and offers relational modes of analysis with spatial and chronological forms of contextualisation. By combining these elements within one environment, scholars are able to instantly process, analyse and visualise complex datasets relationally, diachronically and spatially; trailblazing.
nodegoat follows an object-oriented approach throughout its core functionalities. Borrowing from actor-network theory this means that people, events, artefacts, and sources are treated as equal: objects, and hierarchy depends solely on the composition of the network: relations. This object-oriented approach advocates the self-identification of individual objects and maps the correlation of objects within the collective.
Data Modelling
In nodegoat users define their own data models freely and dynamically with no limitations to relational structures or depths. This model allows for filtering and analysis of complex relational networks between Objects in your datasets. Each Object can be supplemented with geographical and temporal attributes, making diachronic geographic and social visualisations of your datasets directly available.
You are free to implement a data model of your own design, or create a data model in alignment with existing vocabularies (e.g. Dublin Core, or the CIDOC Conceptual Reference Model).
Read the blog post 'What is a Relational Database?' to learn more about the basics of data modelling. The blog series 'How to store uncertain data in nodegoat' discusses how various levels of uncertainty that are found in historical sources can be stored in your nodegoat environment.
Follow the 'Getting Started' guides to learn how to create a data model in nodegoat.
Data Creation & Exploration
nodegoat can host multiple projects with different relational data models and manage users with various privileges and project affiliations. With the integration of version history, every change made to the data is stored and documented; users can work on different aspects of the datasets together.
Individual scholars and collaborative research projects use nodegoat to build new datasets by means of manual data entry processes. If pre-existing data collections exist, they can be ingested by means of the import module. The 'Import Data' section of the nodegoat Guides will walk you through the process of importing data.
Analysis
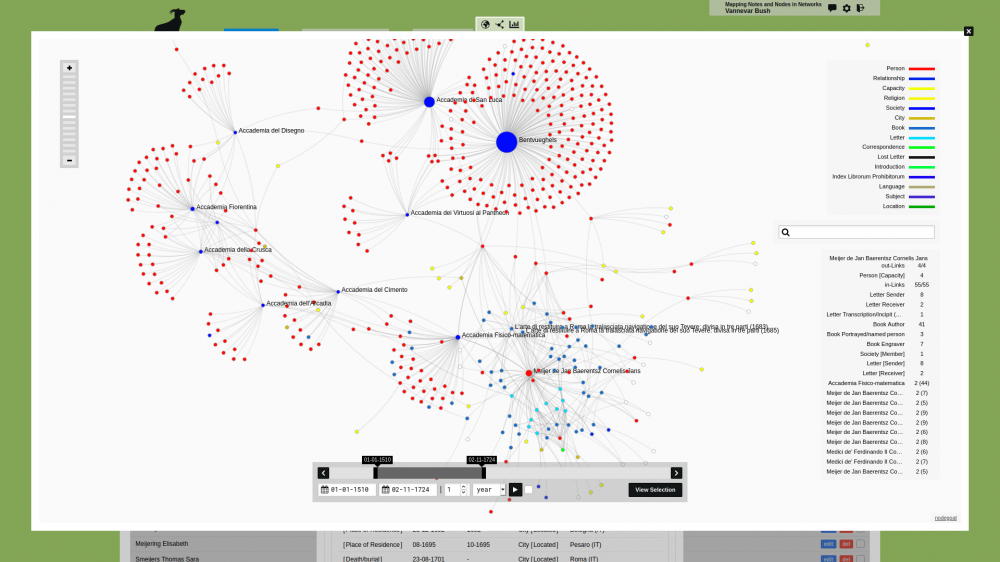
nodegoat is capable of processing complex queries. In nodegoat you query your data by means of filtering functionalities. These filters are based on the data model and can be complex or simple. Each filter can be stored and reused by other users and can be used for various functionalities and administrative tasks within a research project.
nodegoat guides the exploration and analysis of datasets by mapping relational paths formulated by the data model. The resulting graphs can be explored with the ability to test conditions formulated by the user and the ability to apply network analytical measures and metrics. The analysis functionality allows you to calculate the degree centrality, betweenness centrality, or another metric for each Object in your nodegoat environment.
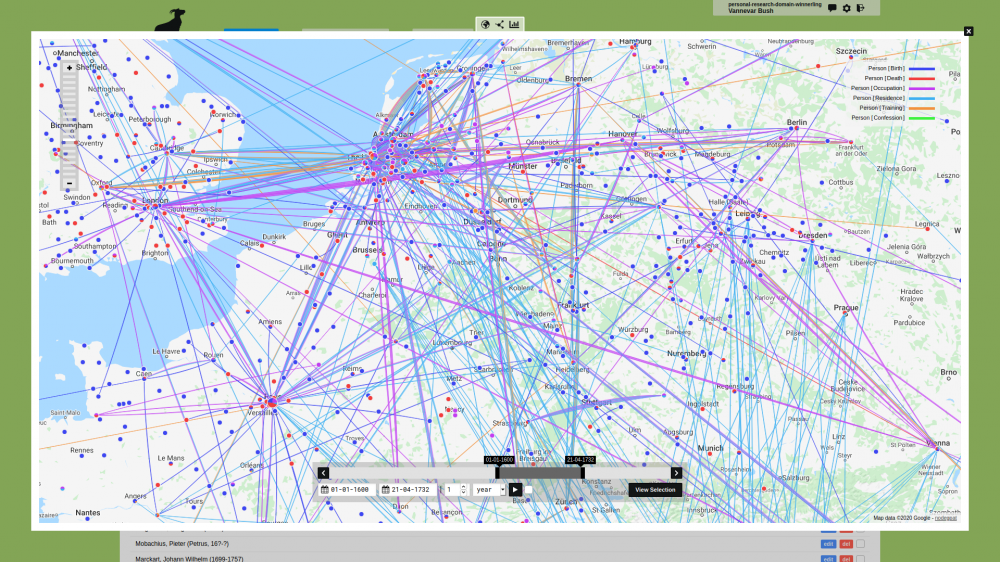
Spatial Data
Every Object in nodegoat can have various spatial contexts. nodegoat offers multiple ways in which you can record spatial statements. You can create relational spatial statements, you can store latitude and longitude values, or you can store geometrical statements in the form of GeoJSON. You can make use of custom (historical) maps in your geographical visualisations. These features make nodegoat an ideal tool for creating deep maps, or a custom gazetteer. The section 'Working with Spatial Data' of the nodegoat Guides covers the full range of spatial functionalities that are offered in nodegoat.
Temporal Data
Every Object in nodegoat can have various temporal contexts. You can store dates, periods, or complex Chronology Statements in nodegoat. Chronology Statements are formatted as ChronoJSON and allow you to express vague dates, custom cycles, and relational dates. The section 'Working with Temporal Data' of the nodegoat Guides describes the various ways in which you can store temporal data in nodegoat.
Textual Data
nodegoat allows users to define in-text references to any Object in your dataset. These references are saved as a relation between the text and the tagged Object.
Using nodegoat's reconciliation functionalities textual data can be automatically matched and linked with Objects stored in your nodegoat environment. The section 'Reconcile Textual Data' of the nodegoat Guides describes various use cases on how you can link your texts with Objects.
Linked Data
nodegoat integrates and assists linked data connectivity. Users can configure various SPARQL endpoints and API resources for easy and consistent usability. Linked data resources can be dynamically queried and filtered to ingest data or establish URI-based links. The section 'Ingestion Processes' of the nodegoat Guides describes how to link, connect, and use data from external repositories.
Source Referencing
nodegoat fully integrates source documentation and annotation (e.g. management of bibliographical data) in order to properly reference datasets. It is possible to save an extensive list of sources for each Object and each Object Description. This functionality will build a bibliographical file in nodegoat and link books, journal articles and other sources to entered data. You are able to reference sources per Object Description to facilitate cases of complex or conflicting sources.
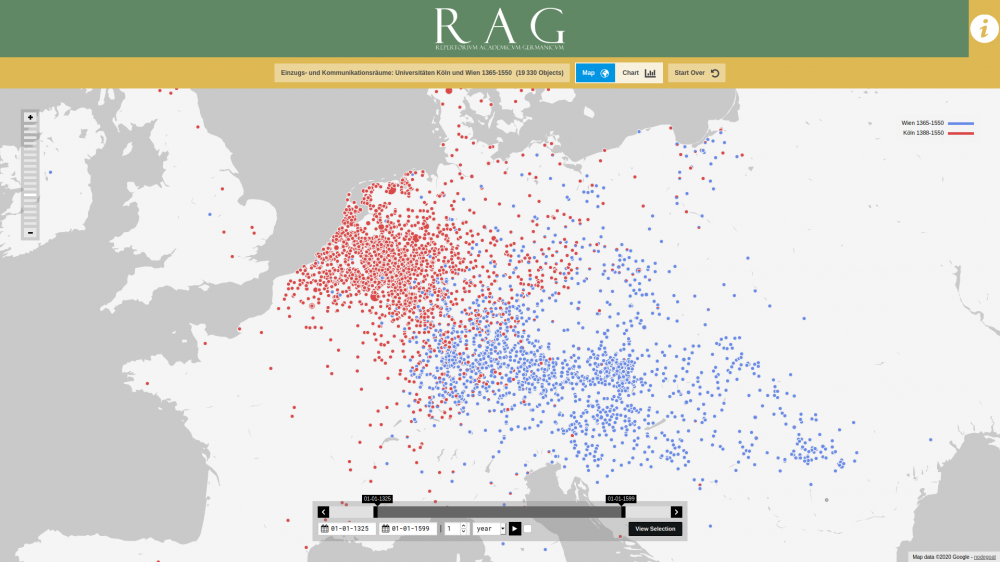
Visualisations
You can instantly visualise your data from within your nodegoat environment. The nodegoat visualisations are always diachronic. Geographical visualisations allow you to explore your data through time and space. Social network visualisations allow you to explore the way in which relationships develop over time.
Export & Publication
nodegoat is built to be fully platform independent. It is possible to import complex and relational datasets from file and to export clean relational datasets in CSV, ODT, and JSON. nodegoat's API provides access to all of nodegoat's core functionalities, such as: project-based access to data and data model, user authentication, filters, conditions, relational path-based output, and URI management. The section 'Export Data' of the nodegoat Guides provides various examples on how to connect your nodegoat environment to practically any external resource.
nodegoat allows users to share data and research outcomes with a large audience by means of interactive public user interfaces. Public user interfaces can be configured to provide access to published data (specific datasets or analytical configurations and visualisations), or be of more experimental nature and provide open access to a project's research data.
Cite nodegoat
Bree, P. van, Kessels, G., (2013). nodegoat: a web-based data management, network analysis & visualisation environment, http://nodegoat.net from LAB1100, http://lab1100.com