Linking your Historical Sources to Open Data: workshop series organised by COST Action NEP4DISSENT
CORE Admin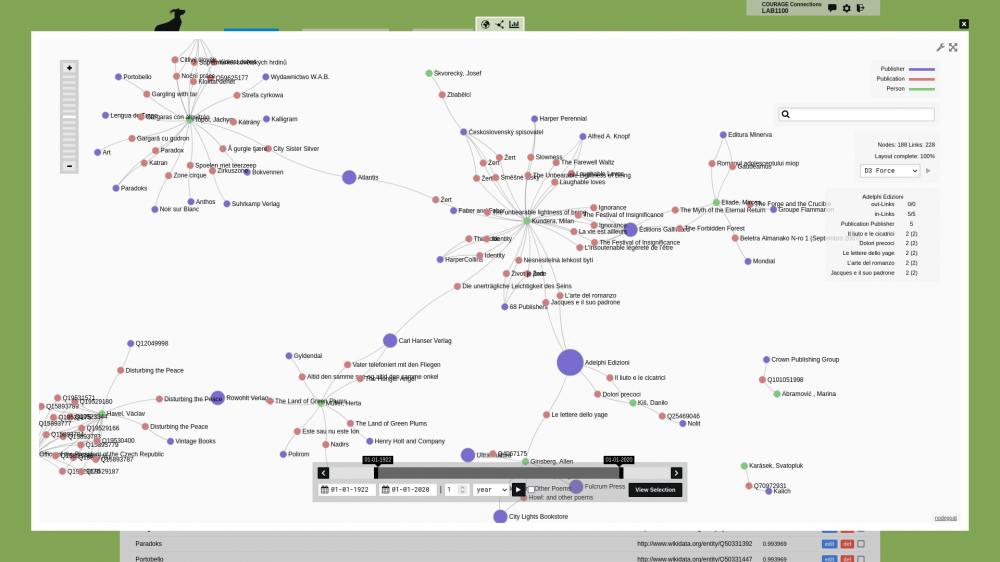
The workshop series ‘Linking your Historical Sources to Open Data’ organised by the COST Action NEP4DISSENT aims to help researchers to connect their research data to existing Linked Open Data resources. These connections will ensure that research data remains interoperable and allow for the ingestion of various relevant Linked Open Data resources.
In two workshop sessions we will discuss the basic principles of Linked Open Data and show you how your project can benefit from this. We will do this by setting up a nodegoat environment and connect this to Linked Open Data resources. Data that has been collected in the COURAGE registry will be used to demonstrate how these connections can be set up. The COURAGE registry can be explored here, the data is available for download here. If you already have a configured nodegoat environment, you can use this during the workshop.
The workshops will take place on 13-09-2021 and 20-09-2021. All sessions take place between 14:00 and 17:00 CEST. We will be using Zoom and will record the sessions so you can rewatch them. The sessions will be hosted by Pim van Bree and Geert Kessels of LAB1100 and Jessie Labov of the Institute of Literary Studies, Humanities Research Center, Eötvös Loránd Research Network, representing the NEP4DISSENT network.
Click here to register for the workshops. Registration closes on September 10.
Session 1: 13-09-2021: 14:00-17:00 CEST
After a brief introduction to NEP4DISSENT, COURAGE, Linked Open Data, and nodegoat, we will implement a data model in your own nodegoat environment. This data model will focus on people and publications. Once the data model is up and running, we will manually enter a small amount of data to evaluate your data model. We will then import a CSV file that contains a subset of the people that are part of the COURAGE registry.
At the end of the session we will set up a first Linked Data Resource that will connect to Wikidata. We will use this to ingest VIAF identifiers for the people mentioned in the COURAGE dataset.
Session 2: 20-09-2021: 14:00-17:00 CEST
In this session we will ingest publication data from Wikidata to enrich the subset of the COURAGE dataset we imported in the previous session. We will first expand the data model so we can accommodate the new data. We will then look at some SPARQL queries that we can use to extract the data we need from Wikidata. Once we are able to identify the data we need, we will ingest this into your own nodegoat environment by means of Linked Data Resources and Ingestion Processes.
We will also look at some simple Conversion scripts that allow you to align the external data formats with the data in your own environment.
These workshops follow a workshop series earlier this year, organised in collaboration with the University of Bern in the framework of the SNFS SPARK project 'Dynamic Data Ingestion’ as well as two iterations of the NEP4DISSENT Summer Schools (2019: Cultures of Dissent in Eastern Europe (1945-1989): Research Approaches in the Digital Humanities, 2021: ‘Cultures of Dissent in Eastern Europe (1945-1989): Research Approaches in the Digital Humanities - Online’).
This workshop series is supported by a COST Action Virtual Mobility Grant awarded by the COST Action CA16213.
 |  |  |
Comments
Add Comment