Elif Derin-Can of the Fatih Sultan Mehmet Vakıf Üniversitesi organises a nodegoat workshop on March 2 within the framework of the Digital Ottoman Studies initiative. You can read more about this here and register via this link.[....]
Together with the Research School Political History we will run a workshop with the title ‘Data management and analysis for historical research in nodegoat’ on 23 October 2023. The workshop takes place between 10:00 and 17:00 at the Oost-Indisch Huis in Amsterdam. This is an in-person event and registration is required. Registration deadline is 9 October.
Thanks to the Allmaps project, it is now possible to use any map that has been published as a IIIF image as a background map in your geographic visualisations in nodegoat.
The International Image Interoperability Framework (IIIF) is a set of open standards for publishing digital objects, maintained by a consortium of cultural institutions. The list of institutions that publish their digitised maps as IIIF images is constantly growing. This overview provides a number of examples of available resources. The David Rumsey Map Collection also contains a large number of maps that have been published as IIIF images.
nodegoat Users have been able to use (historical) maps that are published as XYZ-tiles. We have now updated our Guide 'Use a Historical Map' to describe the steps you need to take to use IIIF images as a background map for your geographic visualisations in nodegoat. The Guide uses an example of a historical map published in the Digital Collections of Leiden University Libraries.
On Wednesday 11 October 2023 we will run a nodegoat Workshop at Stockholm University. The workshop will take place between 10.00 and 16.30 at Bergsmannen, Stockholm University. This is an in-person event and registration is required. Registration deadline is 27 September.
The Scope functionality is used throughout nodegoat to traverse your data model and select elements to be included in a visualisation, analysis, or export. With the Scope, you can limit or expand your data selection. In a prosopographical analyses you might want to include all educational institutes related to one person, plus all the relations of these institutes, while omitting all other personal relations of a person. Follow this Guide to learn how to configure a Scope.
Chronology Statements that you make in nodegoat allow you to specify what you mean by a statement like 'circa'. Instead of using qualitative statements about vagueness, Chronology Statements provide you with a way of making quantitative statements about vagueness. Chronology Statements also allow you to make relational date statements: 'the date point is between the sending of letter X and the sending of letter Y'. Follow this Guide to learn how to store uncertain dates by using Chronology Statements and follow this Guide to learn how to store relational dates by using Chronology Statements.
The temporally-aware dynamic network analysis functionality makes the temporal options offered by the Chronology Statements available on any level of a Scope. This allows you to apply and pass temporality to time-bound connections in any of a Scope's paths. The dates from Chronology Statements can be sourced from every step in the traversal: ascendant or descendant nodes, and combinations. Selected configurations can be applied on any/all of the connections/edges: outbound or inbound directionality, and combinations.
Example: Academic Connections
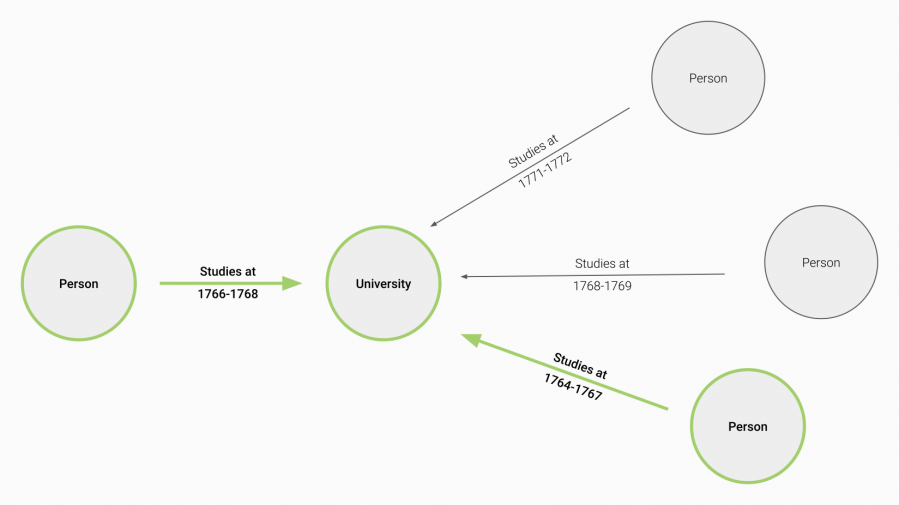
With this functionality it is now possible to dynamically generate networks of people who attended the same educational institute at the same time, without specifying any dates in a filter. The temporally-aware dynamic network analysis functionality applies the initial date on every other relationship that appears on a specified path:
Two persons shown having an overlapping academic connection out of four persons.
The obvious benefit of this approach is the scalability of this functionality, as it allows you to quickly scrutinise complex networks based on time-bound connections:[....]
This year the Leipzig Research Centre Global Dynamics (ReCentGlobe) has set up a nodegoat Grow installation to service two multi-year research projects. The project 'Die Produktion von Weltwissen im Umbruch' uses nodegoat to analyse the globalisation of knowledge production by mapping the development of Area Studies and Global Studies in the German context over the past 15 years. The project 'African non-military conflict intervention practices' uses nodegoat to build a comprehensive database of non-military interventions since 2004 by the African Union and by Regional Economic Communities.
As a result of this collaboration, the ReCentGlobe initiative organises a public nodegoat workshop within the framework of the Digital Lab infrastructure. The workshop will take place at the ReCentGlobe institute on 25 July 2023. More information about the programme and registration can be found here.
The TIC-Collaborative project of Ghent University and Maastricht University has published a dataset on international social reform congresses and organisations (1846-1914). This dataset has been created and maintained in a nodegoat installation at Ghent University since early 2014.
The data has been published as CSV files in the 'IISH Data Collection' repository and can be downloaded here. The dataset contains 1206 organisations, 1052 publications, 23247 people, 1690 conferences, and 35609 conferences attendance statements. All these statements have been enriched with spatial-temporal attributes which allows for the diachronic and geographic analysis and exploration of the relational data.[....]