Release of new nodegoat Features
CORE Adminnodegoat has been extended with four new features in the past months. These new features were commissioned by three research projects from Switzerland, Slovenia, and The Netherlands. All nodegoat users can now make use of these features.
Data Model Viewer
This feature has been commissioned by the Historical Institute of the University of Bern for the REPAC project.
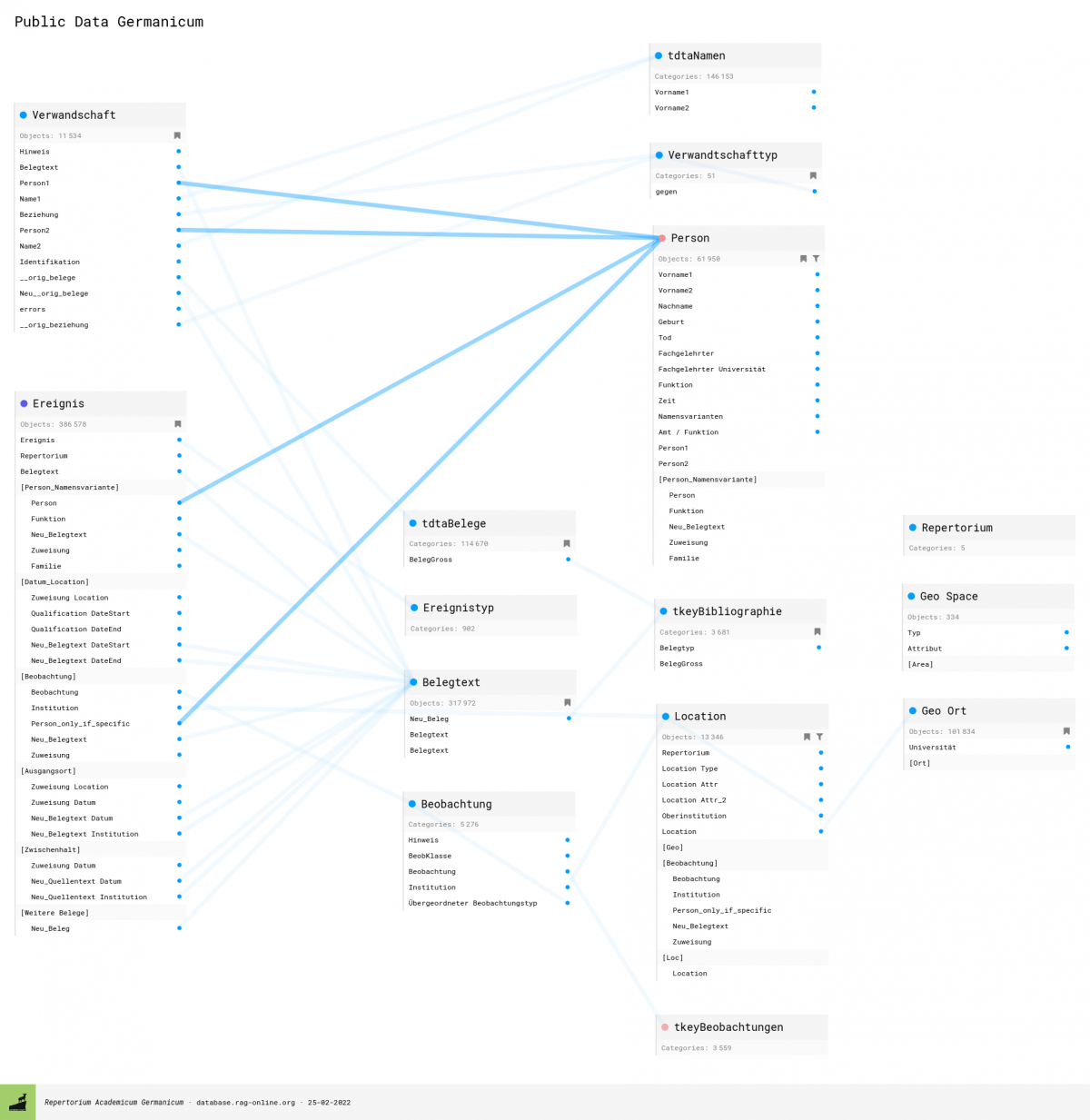
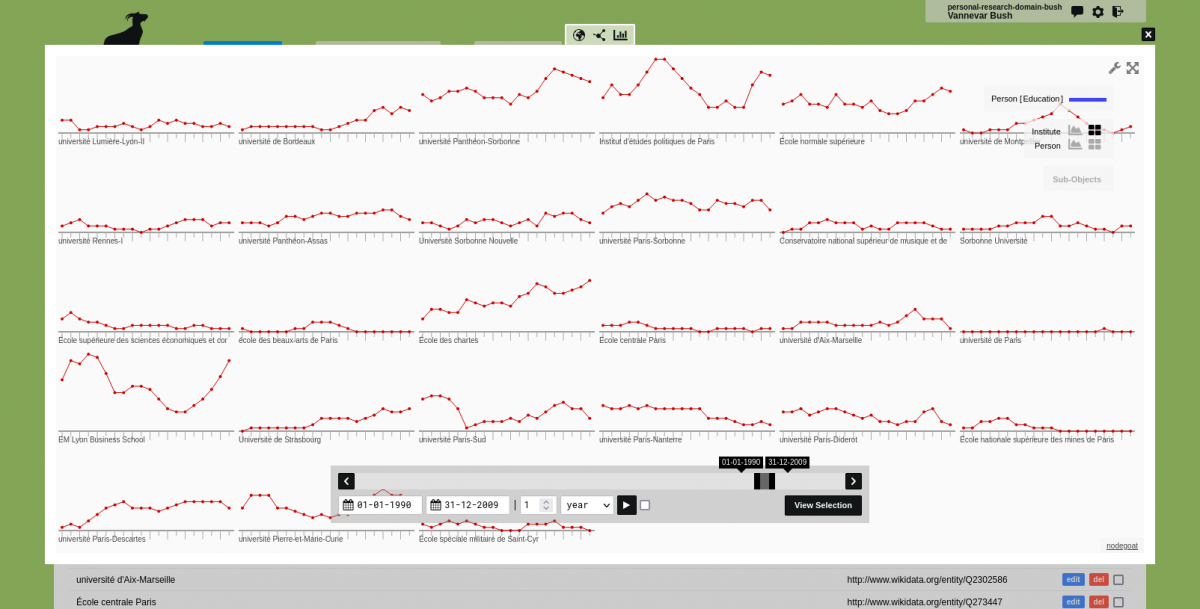
When the complexity of the data model that you have implemented in nodegoat grows, it might be challenging to maintain an overview of all the Object Types, Object Descriptions, Sub-Objects, Sub-Object Descriptions, and all the relationships in between these elements. You can now generate an overview of all the elements of your data model that have been enabled in a Project.
Go to 'Management' and click the name of a Project that is listed in the overview of Projects. Set the 'Mode' to 'References Only' to hide all non-relational elements. Set the 'Size' to 'Full Height' to expand the height beyond the size of the window. You can specify a DPI value and download a 'png' version of the generated overview. To enhance the legibility of the graph you can reposition elements by means of dragging and dropping.[....]