Linked Data vs Curation Island
CORE AdminYou can now use nodegoat to query SPARQL endpoints like Wikidata, DBpedia, the Getty Vocabularies (AAT, ULAN, TGN), and the British Museum. Through the nodegoat graphic interface you query linked data resources and store their URIs within your dataset. This means that you can search all people in Wikidata using the string 'Rembrandt' and select the URI of your choice (e.g. 'https://www.wikidata.org/wiki/Q5598'). By doing so, you add external identifiers to your dataset and introduce a form of authority control in your data. This will help to disambiguate objects (like persons/artworks with similar names) and also enhances the interoperability of your dataset. Both these aspects make it easier to share and reuse datasets.
These two advantages (data disambiguation and data interoperability) are useful for researchers who work on small(-ish) but complex datasets. Researchers who feel that 'automated' research processes are unattainable for them as their data may be dispersed, heterogeneous, incomplete, or only available in an analogue format, are more likely to rely on something like the old fashioned card catalogue system in which all relevant objects and their varying attributes and relations are described. Luckily, we can also use digital tools to create and maintain card catalogues (databases). For a historian who is mapping the art market of a seventeenth century Dutch town, a database is a very powerful tool to store and analyse all objects (persons, artworks etc.) and the relations between these objects. Still, if no external identifiers are used, this dataset is nothing but a curated island (even if the data is published!).

Curation & Linked Data
The process we describe here aims to connect the craftsmanship of research in the humanities to the interconnected world of massive repositories, graph databases and authority files. Other useful purposes of linked data resources for the humanities have already been described extensively, like using aggregation queries to analyse large collections, thesaurus comparison/matching, or performing automated metadata reconciliation as described by the Free Your Metadata initiative.
The creation of a dataset on correspondence networks is an example of a use case for manually storing URIs as external identifiers/authority records in nodegoat. If researchers include a Wikidata/DBPedia URI for every person in the dataset, data disambiguation is already mostly dealt with. (A major obstacle here is of course that for the majority of people, no URI is available.) Moreover, if the dataset is published, it is immediately ready for reuse as other researchers know which person is meant by each name. Plus, the usage of these identifiers have made the dataset immediately usable for a harvester like correspSearch which connects various collections of letters (by means of comparing URIs of persons in the correspondence networks).
This process is beneficial for any project in which disambiguation and enhancing interoperability is valued. This is also the case for the TIC-project at the Ghent University and Maastricht University in which congress participation in the long nineteenth century is mapped and analysed. Here, objects of persons will also be linked to external identifiers. This project initiated and supported the development of the Linked Data Module in nodegoat.
Configuration
If you're unfamiliar with Linked Data/RDF/SPARQL, we recommend you to read the excellent SPARQL tutorial by Matthew Lincoln. You can also explore various endpoints through an interface:
- Wikidata: info, example queries, interface
- DBPedia: info, example queries, interface
- British Museum: info, example queries, interface
- The Getty Vocabularies: info, example queries, interface
Before you start using any linked data resource, it is best to first familiarise yourself with the structure of the endpoint and with the scope of the provided content. Also, as some endpoints may struggle with performance/uptime, it is good to regularly check its status.
In the Linked Data Module you configure how nodegoat should communicate with linked data resources. Here you have to define the URL of a SPARQL endpoint and possibly set additional options (e.g. for DBpedia, URL: 'http://live.dbpedia.org/sparql?query=' & URL Options: '&format=json'). Next, you enter the query you want to use. The idea here is that you specify variables inside this query that you want to be able to change while searching for URIs. So if you want to search for objects based on their labels, you create a query in which you use the tags [query=name][variable]x[/variable][/query] to be able to dynamically set the string that will be used to filter the labels. Let's look at this by means of an example:
We will start with a straightforward example query, like:
SELECT ?subject ?label
WHERE {
?subject rdfs:label ?label .
FILTER (CONTAINS(?label, 'x')) .
}You can test this query in one of the GUIs mentioned above. We recommend that you add LIMIT 10 at the end of query so you won't overburden the endpoint. This query gets all the subjects that have the predicate rdfs:label and filters them on the presence of an 'x' in this label.
Because we want to be able to change the 'x' in the string we add the following tags:
SELECT ?subject ?label
WHERE {
?subject rdfs:label ?label .
[query=name]
FILTER (CONTAINS(?label, '[variable]x[/variable]')) .
[/query]
}These tags tell nodegoat that the value 'x' may be specified by the user. To complete this example, we have to give this Linked Data Resource a name and set the URL: 'https://query.wikidata.org/bigdata/namespace/wdq/sparql?query=', and URL Options: '&format=json' (or 'http://live.dbpedia.org/sparql?query=' and '&format=json', or for the British Museum only the URL: 'http://collection.britishmuseum.org/sparql.json?query=').
Click the green 'test' button to test this query. If everything has been configured correctly, a JSON response will appear in the response area. By clicking the green 'use' button, you can use this response to specify the location of the URI and label that will be used by nodegoat. Your final configuration should look like this:
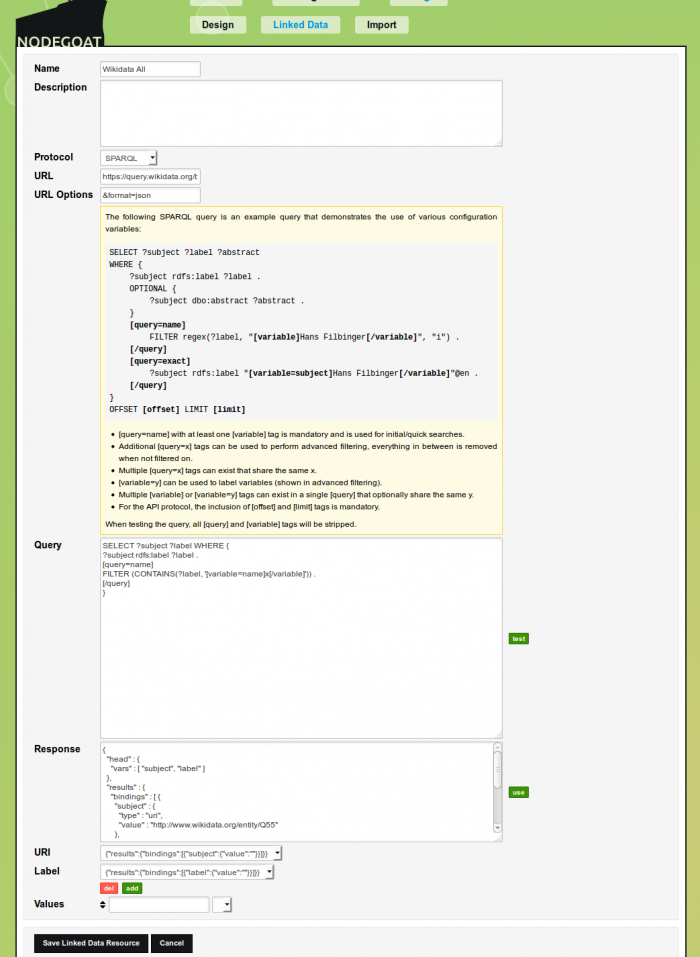
Optionally you can select additional values from your SELECT that you want to use in your results browser (more on that below).
Click 'Save Linked Data Resource' and create an Object Description in your Data Design that uses this resource (via the Object Description type 'External'). You may also want to tick the first checkbox there to allow for multiple URIs per object. In Data you can now dynamically query the resource of your choice based on the string you enter in this Object Description (a request is made after a 3 second delay). By clicking on the grey filter button in the dropdowns, you can also inspect and filter the results in depth, or switch to other Linked Data Resources you have configured. Clicking/selecting an URI assigns it to the Object.
Of course the simple query above doesn't make much sense (as it's unlikely that your research topic covers everything in wikipedia/the British Museum), but we wanted to start of as easy as possible. From here, you could limit the initial selection in the Wikidata query to persons only:
PREFIX wd: < http://www.wikidata.org/entity/>
PREFIX wdt: < http://www.wikidata.org/prop/direct/>
SELECT ?p ?label (CONCAT(STR(DAY(?dob)),"-",STR(MONTH(?dob)),"-",STR(YEAR(?dob))) as ?displaydob) (CONCAT(STR(DAY(?dod)),"-",STR(MONTH(?dod)),"-",STR(YEAR(?dod))) as ?displaydod)
WHERE {
?p wdt:P31 wd:Q5 .
?p rdfs:label ?label FILTER (lang(?label) = "en") .
OPTIONAL { ?p wdt:P569 ?dob }.
OPTIONAL { ?p wdt:P570 ?dod }
[query=name]
FILTER (CONTAINS(lcase(str(?label)), lcase(str('[variable=name]g[/variable]')))) .
[/query]
}Here, we've included the date of birth and death as well. You can select these values so they are shown in the results browser.

SELECT values.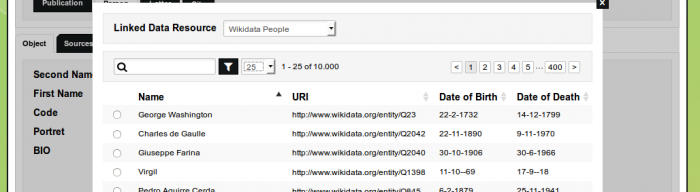
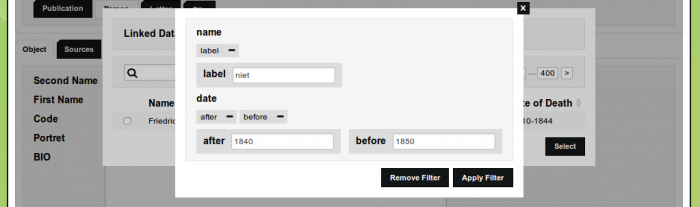
SELECT values in the results browser.Next, we limit the initial selection even more to only include philosophers. Moreover, we've added an additional query tag that will allow us to filter on the date of birth (on wikidata):
PREFIX wd: < http://www.wikidata.org/entity/>
PREFIX wdt: < http://www.wikidata.org/prop/direct/>
SELECT ?subject ?label (CONCAT(STR(DAY(?dob)),"-",STR(MONTH(?dob)),"-",STR(YEAR(?dob))) as ?displaydob) (CONCAT(STR(DAY(?dod)),"-",STR(MONTH(?dod)),"-",STR(YEAR(?dod))) as ?displaydod)
WHERE {
?subject wdt:P106 wd:Q4964182 .
?subject rdfs:label ?label FILTER (lang(?label) = "en") .
?subject wdt:P569 ?dob .
?subject wdt:P569 ?dod .
[query=name]
FILTER (CONTAINS(lcase(str(?label)), lcase(str('[variable=label]a[/variable]')))) .
[/query]
[query=date]
FILTER (?dob >= "[variable=after]1500[/variable]-01-01"^^xsd:dateTime && ?dob <= "[variable=before]1700[/variable]-01-01"^^xsd:dateTime) .
[/query]
}
Custom SPARQL-endpoint Browser
Even though the Linked Data Module has been developed to foster interoperability and sustainable data curation, it turned out to have another benefit as well: data exploration! PhD student Ingeborg van Vugt, who has been using nodegoat since the Mapping Notes and Nodes project, pointed out to us that she queried an endpoint through nodegoat to find variations and additional information on her data. This made us realise that the Linked Data Module allows researchers to query endpoints (for finding paintings of different artists, finding different publications of the same book, or finding artefacts produced in different periods) without having to type/copy-paste the query over and over again. As you can set the values that are collected from the endpoint, you can customise the result to display information relevant to your research question. The results are subsequently shown in a table, making it easy to compare them. Changing the variables in your query can be easily done by changing the filtering in the results browser.
Query Examples
We describe other examples below and will keep updating them. If you have a good use case, please let us know so we can add it here as well.
1. British Museum
As we've already mentioned, we recommend you to first explore the endpoint before you start building your query. For the British Museum you can run a query to list all object types that have been used to classify their objects, and see what kind of broader object types are used, to make a query that lists all the object types within the broader object type "visual representation". Once you know that the object type "drawing" is used a great deal, you can list the artists who made the drawings. From there you can create a query that finds you all the drawings by Rembrandt (based on the tutorial of Matthew Lincoln, where you'll find a much richer explanation of these kind of examples).
We can now edit this query to make it work in nodegoat:
SELECT ?object ?identity_label ?date ?description ?type_label ?person
WHERE {
?object bmo:PX_object_type ?type .
[query=type]
?type skos:prefLabel "[variable=label]drawing[/variable]" .
[/query]
?object ecrm:P108i_was_produced_by ?production .
?production ecrm:P9_consists_of ?production_node .
?production_node ecrm:P14_carried_out_by ?person .
?person rdf:type ecrm:E21_Person .
[query=name]
?person skos:prefLabel "[variable=label]Rembrandt[/variable]" .
[/query]
?production ecrm:P9_consists_of ?date_node .
?date_node ecrm:P4_has_time-span ?timespan .
?timespan ecrm:P82a_begin_of_the_begin ?date .
[query=date]
FILTER(?date >= "[variable=after]1500[/variable]-01-01"^^xsd:date && ?date <= "[variable=before]1700[/variable]-01-01"^^xsd:date)
[/query]
OPTIONAL {
?object ecrm:P48_has_preferred_identifier ?identity .
?identity rdfs:label ?identity_label .
}
OPTIONAL {
?object bmo:PX_physical_description ?description .
}
}
With this you can search for objects by specifying the type of object, its maker and a timeframe in which the object was made. See the youtube clip above or log in to nodegoat using the username 'demo_rembrandt' and password 'demo' to test this query yourself.
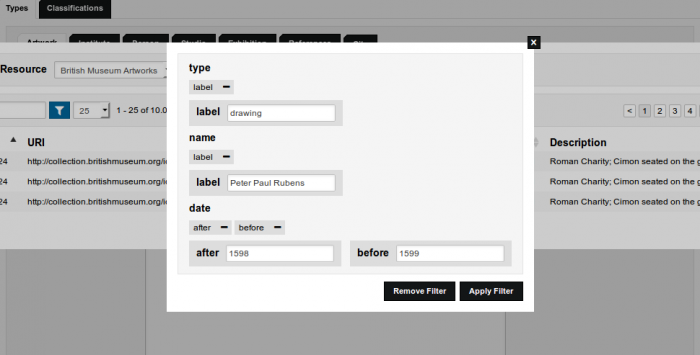
One caveat we want to make here is that for the sake of speed we opted to search for exact strings, which works well for labels of classifications, but once you search for names, this becomes problematic. ?person skos:prefLabel "Rembrandt" gives results, but ?person skos:prefLabel "rembrandt" doesn't, just like ?person skos:prefLabel "Rubens" will not give you any results but ?person skos:prefLabel "Peter Paul Rubens" will. A way to avoid this is to use something like FILTER (CONTAINS(lcase(str(?label)), "rubens")) instead. This checks if the lowercase string of the label contains the string "rubens". Another option is to use a regular expression like FILTER regex(?label, "rubens", "i"). Both of these options work well in their interface as you don't need to wait for the first results to load. From a different client the query needs to collect a certain amount of results before it's sent, which will test your patience.
Next to artists, we can also look at the subject matter of the objects, and list the most depicted entities. With this, we can create a query for finding vessel related objects (e.g. amphoras) by means of depicted entities and production period. Again, we opted for exact strings, like 'Zeus/Jupiter', 'Apollo' or 'Athena/Minerva', but this can be done as well with fuzzy searches. To get all the kinds of amphoras, we used the broader type "vessel", which can be changed to "currency" to get different kinds of coins.
SELECT ?object ?identity_label ?type_label ?description ?date
WHERE {
?object ecrm:P62_depicts ?depicted .
[query=name]
?depicted skos:prefLabel "[variable=label]Apollo[/variable]".
[/query]
?object ecrm:P108i_was_produced_by ?production .
?object bmo:PX_object_type ?type .
?type skos:prefLabel ?type_label .
?type skos:broader ?broader_type .
[query=type]
?broader_type skos:prefLabel "[variable=label]vessel[/variable]".
[/query]
?production ecrm:P9_consists_of ?date_node .
?date_node ecrm:P4_has_time-span ?timespan .
?timespan ecrm:P82a_begin_of_the_begin ?date .
[query=date]
FILTER(?date >= "[variable=start]-1000[/variable]-01-01"^^xsd:date && ?date <= "[variable=end]-0100[/variable]-01-01"^^xsd:date) .
[/query]
OPTIONAL {
?object ecrm:P48_has_preferred_identifier ?identity .
?identity rdfs:label ?identity_label .
}
OPTIONAL {
?object bmo:PX_physical_description ?description .
}
}2. Dutch Royal Library - STCN
The following query searches the Short-Title Catalogue, Netherlands (STCN) for its records on persons. Here, [variable=name] is used to search both labels and alternate labels.
SELECT ?record, ?name, ?birth_date, ?death_date, ?identifier, ?note
WHERE {
?record dc:type "person"@en.
?record skos:prefLabel ?name.
OPTIONAL {
?record schema:birthDate ?birth_date.
?record schema:deathDate ?death_date.
?record skos:exactMatch ?identifier.
?record skos:editorialNote ?note.
}
[query=name]
?record skos:altLabel ?name_alt.
FILTER (CONTAINS(lcase(str(?name)), lcase(str('[variable=name]a[/variable]'))) || CONTAINS(?name_alt, '[variable=name]a[/variable]'))
[/query]
[query=note]
FILTER (CONTAINS(?note, '[variable]a[/variable]'))
[/query]
}3. Getty Vocabularies
Based on this example query you can create a query to search for AAT concepts while specifying a broader concept. This enables you to search for "glass" in a broader concepts like "occupation", to find any glass related occupations. When you assign this Linked Data Resource in nodegoat to a Classification, you are able to connect your Classification Categories to sustainable linked data vocabularies.
SELECT * {
?concept a gvp:Concept; gvp:broaderExtended ?broader.
[query=name]
?concept luc:term "[variable=label]glass[/variable]*".
[/query]
[query=broader]
?broader luc:term "[variable=label]occupation[/variable]*".
[/query]
?concept gvp:prefLabelGVP [xl:literalForm ?concept_label].
?broader gvp:prefLabelGVP [xl:literalForm ?broader_label]
}You can also query ULAN to find artists by searching through their labels:
SELECT DISTINCT ?person ?preflabel {
?person a gvp:PersonConcept .
?person xl:prefLabel ?preflabel_node .
?person xl:altLabel ?altlabel_node .
?preflabel_node gvp:term ?preflabel .
?altlabel_node gvp:term ?altlabel .
[query=name]
FILTER (CONTAINS(lcase(str(?preflabel)), lcase(str('[variable=term]bree[/variable]'))) || CONTAINS(?altlabel, lcase(str('[variable=term]bree[/variable]'))))
[/query]
}Next steps
We have identified two next steps: use data provided by endpoints in nodegoat and publish nodegoat data as linked data.
- The first point would allow users, for example, to augment Objects in nodegoat with data from the Getty Thesaurus of Geographic Names (TGN) based on the Object's corresponding Getty URIs. This would allow you to pull in the latitude and longitude values of locations in nodegoat so they can be used to produce geographic visualisations.
- The second option would be beneficial for researchers who work on obscure persons/entities as this would allow them to provide linked data resources of their own objects.
Comments
Add Comment