This blog post is part of a series on storing uncertain data in nodegoat: 'How to store uncertain data in nodegoat', 'Incomplete source material', 'Conflicting information', 'Ambiguous identities'.
Most scholars think about their research material in terms of nuances, vagueness, and uniqueness, whereas data is perceived as binary, strict, and repetitive. However, working with a digital tool does not mean that you can only work with binary oppositions or uncontested timestamps. On the contrary: by creating a good data model, you are able to include nuances, irregularities, contradictions, and vagueness in your database. A good data model is capable of making these insights and observations explicit. Instead of smoothing out irregularities in the data by simplifying the data model, the model should be adjusted to reflect the existing vagueness, conflicts, and ambiguities.
Before you start to adjust your data model to accommodate uncertainty, you should first try to determine the causes for uncertainty in your data. Most forms of uncertainty in data can be grouped in three categories: incomplete source material, conflicting information, or ambiguous identities.
These types of uncertainty can be dealt with in different ways. The next three blog posts will walk you through a number of possible solutions. The described strategies are not the only possible solutions: each research question is unique and may call for a solution of its own.
Incomplete source material
When the information you need is not available, incomplete, or vague you have to decide if you want to leave the respective parts in your data empty or enter data based on inference or conjecture. Read the blog post 'How to store uncertain data in nodegoat: incomplete source material' to learn how to deal with incomplete source material.
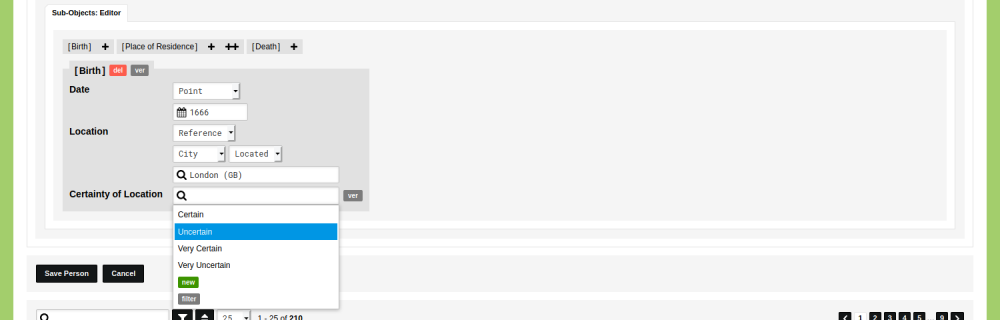
Conflicting information
You might encounter conflicting source material. Two sources might differ about the name of a person, or the date of an event. To account for all possible perspectives, you can include the conflicting statements in your data. Read the blog post 'How to store uncertain data in nodegoat: conflicting information' to learn how to deal with conflicting information.[....]