Together with the Research School Political History we will run a workshop with the title ‘Data management and analysis for historical research in nodegoat’ on 23 October 2023. The workshop takes place between 10:00 and 17:00 at the Oost-Indisch Huis in Amsterdam. This is an in-person event and registration is required. Registration deadline is 9 October.
On Wednesday 11 October 2023 we will run a nodegoat Workshop at Stockholm University. The workshop will take place between 10.00 and 16.30 at Bergsmannen, Stockholm University. This is an in-person event and registration is required. Registration deadline is 27 September.
This year the Leipzig Research Centre Global Dynamics (ReCentGlobe) has set up a nodegoat Grow installation to service two multi-year research projects. The project 'Die Produktion von Weltwissen im Umbruch' uses nodegoat to analyse the globalisation of knowledge production by mapping the development of Area Studies and Global Studies in the German context over the past 15 years. The project 'African non-military conflict intervention practices' uses nodegoat to build a comprehensive database of non-military interventions since 2004 by the African Union and by Regional Economic Communities.
As a result of this collaboration, the ReCentGlobe initiative organises a public nodegoat workshop within the framework of the Digital Lab infrastructure. The workshop will take place at the ReCentGlobe institute on 25 July 2023. More information about the programme and registration can be found here.
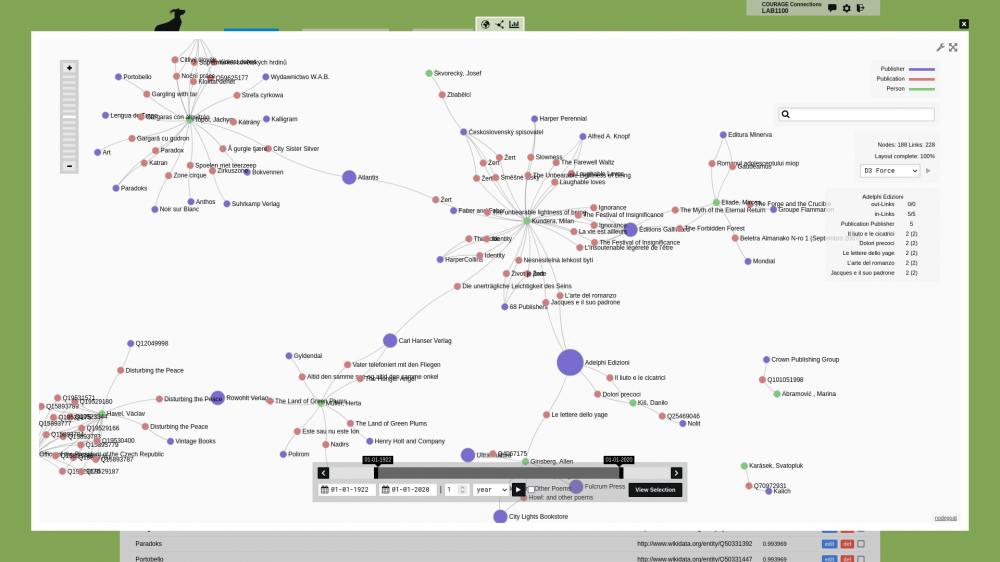
CORE AdminSocial visualisation of a subset of people in the COURAGE registry (in green) enriched with data from Wikidata: publications (in red) and publishing houses (in purple). The size of the nodes of the publishing houses is determined by their PageRank value.
The workshop series ‘Linking your Historical Sources to Open Data’ organised by the COST Action NEP4DISSENT aims to help researchers to connect their research data to existing Linked Open Data resources. These connections will ensure that research data remains interoperable and allow for the ingestion of various relevant Linked Open Data resources.
In two workshop sessions we will discuss the basic principles of Linked Open Data and show you how your project can benefit from this. We will do this by setting up a nodegoat environment and connect this to Linked Open Data resources. Data that has been collected in the COURAGE registry will be used to demonstrate how these connections can be set up. The COURAGE registry can be explored here, the data is available for download here. If you already have a configured nodegoat environment, you can use this during the workshop.[....]
Because this feature is developed in nodegoat, it can be used by any nodegoat user. And because the Ingestion processes can be fully customised, they can be used to query any endpoint that publishes JSON data. This new feature allows you to use nodegoat as a graphical user interface to query, explore, and store Linked Open Data (LOD) from your own environment.
We will organise a series of four virtual workshops to share the results of the project and explore nodegoat's data ingestion capabilities. These workshops will take place on 28-04-2021, 05-05-2021, 12-05-2021, and 26-05-2021. All sessions take place between 14:00 and 17:00 CEST. The workshops will take place using Zoom and are recorded so you can watch a session to catch up.
The first two sessions will provide you with a general introduction to nodegoat: in the first session you will learn how to configure your nodegoat environment, while the second session will be devoted to importing a dataset. In the third session you will learn how to run ingestion processes in order to enrich any dataset by using external data sources. The fourth session will be used to query other data sources to ingest additional data.[....]
In the next weeks nodegoat will be present at several conferences. Meet us in Mainz, Paris, Erfurt, or Pisa to learn more about nodegoat or discuss your nodegoat project with us.
Mainz: Networks Across Time and Space
During the 13th Workshop on Historical Network Research titled "Networks Across Time and Space" we will give a nodegoat workshop and present the recently developed analytical features of nodegoat. This event takes place on May 27th and 28th at the Akademie der Wissenschaften und der Literatur in Mainz.
Paris: Teaching History in the Digital Age – international perspectives #dhiha8
In the past years, we have given various nodegoat workshops to groups of scholars and students. Even though the entry level of the participants varied from workshop to workshop there were similar challenges that emerged every time. These challenges can be grouped into the following three questions:
What is a relational database?
My material is very vague/ambiguous/uncertain/contradictory/unique/special, how can I use this in a database?
How do I use the nodegoat interface?
nodegoat Workshop at the University of Luxembourg.
Since most of the workshops we give are nodegoat-specific, we aim to teach participants how to do data modelling from within the nodegoat interface. Because of this, and as a result of the usual time constraints (often half a day), we have to leave the first two fundamental questions largely untouched. To remedy this, we have written two blog posts in which we aim to cover the first two questions. The third question is being addressed in the nodegoat video tutorials, the FAQ & forum, and in the near future the documentation.[....]
At a certain moment in your research process, you might decide that you need to order your material in a structured format. A reason could be that there are too many different people in your body of research and it's becoming hard to keep track of them, let alone their different attributes. Another reason could be that you have repetitive sources, like letters or books, that you want to store and include in your analysis.
In the old days, you would get yourself a card catalogue and start reworking your notes onto these little handy cards.[....]