How to store uncertain data in nodegoat
CORE AdminThis blog post is part of a series on storing uncertain data in nodegoat: 'How to store uncertain data in nodegoat', 'Incomplete source material', 'Conflicting information', 'Ambiguous identities'.
Most scholars think about their research material in terms of nuances, vagueness, and uniqueness, whereas data is perceived as binary, strict, and repetitive. However, working with a digital tool does not mean that you can only work with binary oppositions or uncontested timestamps. On the contrary: by creating a good data model, you are able to include nuances, irregularities, contradictions, and vagueness in your database. A good data model is capable of making these insights and observations explicit. Instead of smoothing out irregularities in the data by simplifying the data model, the model should be adjusted to reflect the existing vagueness, conflicts, and ambiguities.
Before you start to adjust your data model to accommodate uncertainty, you should first try to determine the causes for uncertainty in your data. Most forms of uncertainty in data can be grouped in three categories: incomplete source material, conflicting information, or ambiguous identities.
These types of uncertainty can be dealt with in different ways. The next three blog posts will walk you through a number of possible solutions. The described strategies are not the only possible solutions: each research question is unique and may call for a solution of its own.
Incomplete source material
When the information you need is not available, incomplete, or vague you have to decide if you want to leave the respective parts in your data empty or enter data based on inference or conjecture. Read the blog post 'How to store uncertain data in nodegoat: incomplete source material' to learn how to deal with incomplete source material.
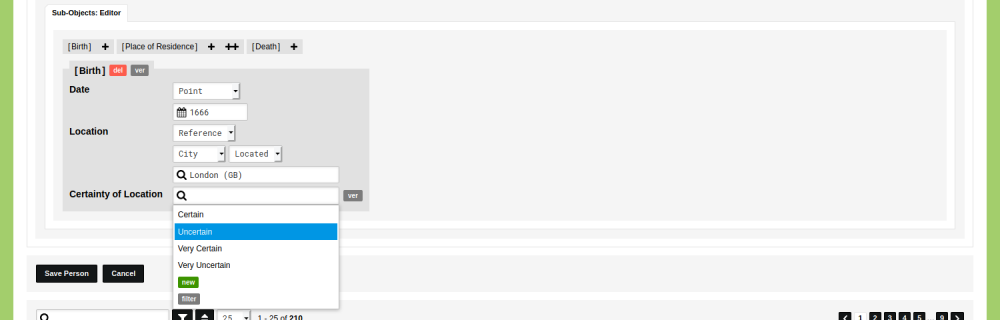
Conflicting information
You might encounter conflicting source material. Two sources might differ about the name of a person, or the date of an event. To account for all possible perspectives, you can include the conflicting statements in your data. Read the blog post 'How to store uncertain data in nodegoat: conflicting information' to learn how to deal with conflicting information.
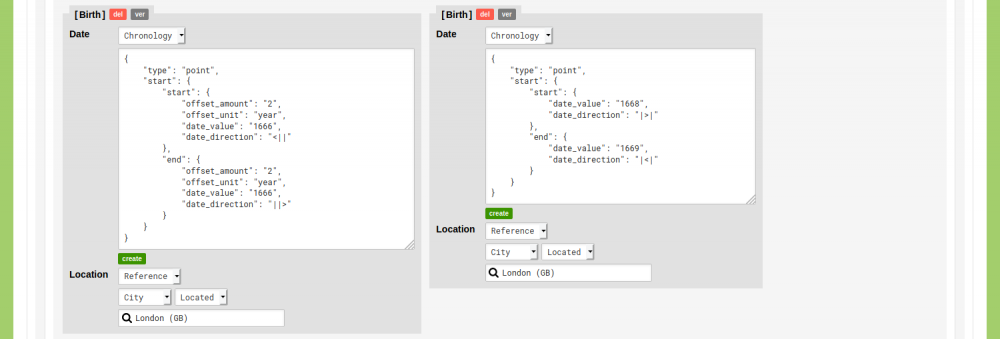
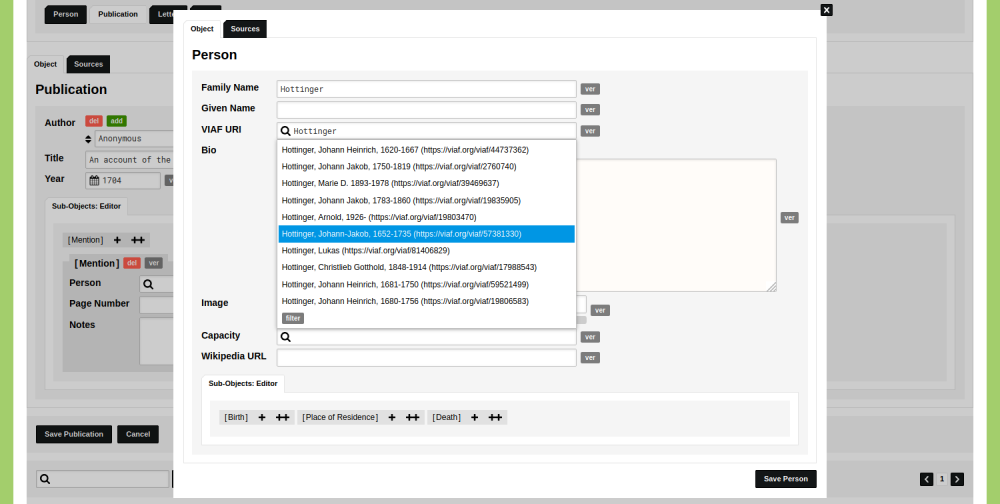
Ambiguous identities
A statement reading 'John Smith was born in Woodstock' is difficult to enter into a database. Without further information, it is impossible to state which John Smith is meant and which place called Woodstock he was born in. Read the blog post 'How to store uncertain data in nodegoat: ambiguous identities' to learn how to deal with ambiguous identities.
You can directly implement the strategies outlined in these three blog posts in your nodegoat environment. In this sense, these strategies should be seen as practical tools that help you to deal with the incompleteness, contradictions, and ambiguity that you find in your source material.
Scholars in the humanities resort to these practical solutions as they lack a theoretical framework that deals with the definition of uncertainty. There are currently no shared standards on how to describe and store uncertain statements.
Existing vocabularies and ontologies (like Dublin Core, or the CIDOC Conceptual Reference Model), are not widely adopted and do not cover the full spectrum of incompleteness, contradictions, and ambiguity found in source material. Different projects have developed different means to deal with uncertainty. A selection of examples is listed below. Just as you can use existing vocabularies or ontologies in your nodegoat environment, you can also implement the following examples in your nodegoat projects.
CIDOC Conceptual Reference Model (CIDOC CRM)
There are lively discussions within the CIDOC CRM ecosystem on how to deal with various kinds of uncertainty. One discussion focuses on the way in which the reliability of statements can be recorded. The discussion can be followed here. One option that is suggested assigns numerical values to measure reliability assessments. Another development that is taking place is the extension of the model with elements that allow for the recording of fuzzy relational dates. CIDOC CRM already supported the use of Allen’s temporal logic (CIDOC CRM properties P114 to P120), recently this has been extended to record fuzzy boundaries of periods (CIDOC CRM properties P173 to P176 and P182 to 185, see version 6.2.7, xix). You can implement this in nodegoat by using four 'Between Statements' in your Chronology Statement. Follow the guide 'Storing Chronology Statements' to learn how to do this.
Text Encoding Initiative (TEI)
Paragraph 21 of the TEI P5 Guidelines deals with 'Certainty, Precision, and Responsibility'. The paragraph covers the usage of 'note' elements to describe uncertain statements, 'certainty' elements to describe the degree of the uncertainty, and 'precision' elements to qualify numerical values. These statements can be very explicit as the degree of uncertainty is expressed by a range of 0.0 to 1.0, and the precision allows for a standard deviation value. When it comes to dates, the guidelines allow for fuzzy periods by combining 'notBefore' and 'notAfter' attributes with low 'precision' values.
Getty ULAN
The editorial guidelines of the Getty Union List of Artist Names (ULAN) has an extensive description on how to record various historical name variants.
Wikidata
The data model of Wikibase, which is used by Wikidata, allows for vague date statements in a way that is very close to the nodegoat Chronology Statements. The model allows for a date value, that is further described by a 'precision' attribute plus a 'before' and 'after' attribute.
Read the other blog posts in this series: 'Incomplete source material', 'Conflicting information', 'Ambiguous identities'.
Tobias Winnerling contributed to this blog post as part of his project 'Charting the process of getting forgotten within the humanities, 18th-20th centuries: a historical network research analysis' (MSCA Action 789672, October 2018-September 2019). Read more about this project on his website fading18-20.hypotheses.org.
Comments
Add Comment