Import Ambiguous Relational Data
This guide demonstrates how to import ambiguous relational data to nodegoat. The guide 'Import Relational Data' describes how disambiguated relational data can be imported to nodegoat. It is best to follow the instructions on importing disambiguated data first to get an understanding of importing relational data. Once you have followed these steps, you can use the steps described below to understand how you can import ambiguous relational data.
In this guide we will import a dataset with personal data: first name, last name, VIAF ID, date of birth, place of birth, date of death, place of death. You can download this data as a Microsoft Excel file, a LibreOffice Calc file, or as a CSV file. Below you see a screenshot of this data in Microsoft Excel.
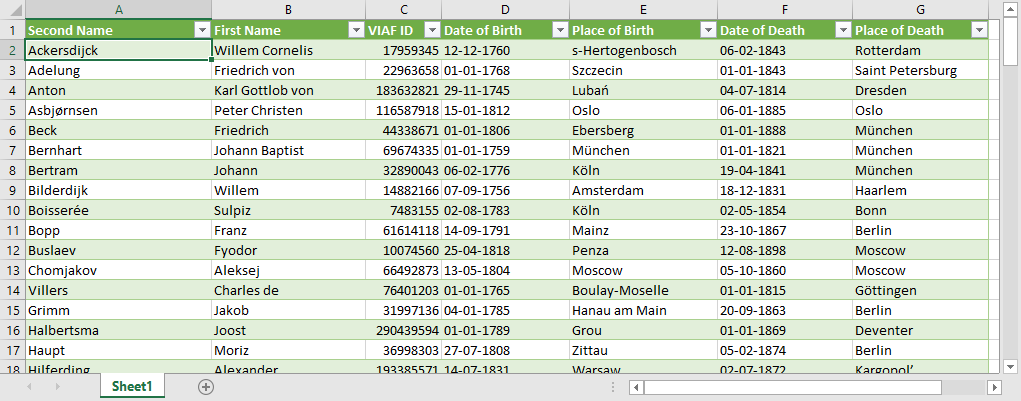
During the import process Objects of the Type 'Person' will be created. Every Object will have two Sub-Objects: 'Birth' and 'Death'. Both Sub-Objects will have a date, supplied by data in the CSV file in the columns 'Date of Birth' and 'Date of Death', respectively. Both Sub-Objects will also have a location, supplied by data in the CSV file in the columns 'Place of Birth' and 'Place of Death', respectively.
The names of the locations listed in the columns 'Place of Birth' and 'Place of Death' are not sufficient to generate geographic visualisations. To be able to visualise locations, you need a latitude and longitude value (e.g. '52.52436829, 13.41053009'). These values are available in nodegoat in the shared Object Type 'City'. This Object Type consists of Objects of places across the world with a population above 5000. All these Objects have latitude and longitude values, e.g. 'Berlin' is located on 52.52436829 latitude, and 13.41053009 longitude. If a person was born in the city of Berlin, you can make a relation to the Object 'Berlin' in the Type 'City', so we know that this person was born somewhere around 52.52436829 latitude, and 13.41053009 longitude. To make this work, the Sub-Object 'Birth' has its location reference set to the Object Type 'City'.
If you search for the city 'Berlin' in the shared Object Type 'City', you notice that there are many cities with the name 'Berlin'. Describing the place of birth of a person by the string 'Berlin' is ambiguous because it is unclear which Berlin is meant. This means that the string 'Berlin' has to be disambiguated. Although it is best to disambiguate your data before importing, nodegoat does offer some help with disambiguating strings during an import process. While you run the import process nodegoat asks which Object of the Type 'City' represents the string 'Berlin', and will store this 'String to Object Pair' for future imports.
Run the import
Upload the CSV file with the personal data. After you have uploaded this file, you go to the tab 'Import Template' and click on 'Add Import Template'. Select the uploaded CSV file that contains the personal data and the target Type 'Person'. Give the Import Template a name like 'My first ambiguous relational import'. Since the import will add new Objects of the Type 'Person' you can leave the Mode set to 'Add New Objects'.
Next, connect the column headings of the CSV file to elements in the Object Type 'Person'. Connect the column heading 'Second Name' to the Object Description 'Family Name'. Connect the column heading 'First Name' to the Object Description 'Given Name'. Connect the column heading 'VIAF ID' to the Object Description 'VIAF ID'. Connect the column heading 'Date of Birth' to the Sub-Object 'Birth' Date Start. Connect the column heading 'Place of Birth' to the Sub-Object 'Birth' Location Reference. Connect the column heading 'Date of Death' to the Sub-Object 'Death' Date Start. Connect the column heading 'Place of Death' to the Sub-Object 'Death' Location Reference.
Every relational element has an additional drop-down menu with the label 'Element that will be used to make a Reference. If left blank, Quicksearch Descriptions will be used.' Since we do not rely on unique identifiers to identify the locations, you can leave this blank.
Your Import Template should now look like this:
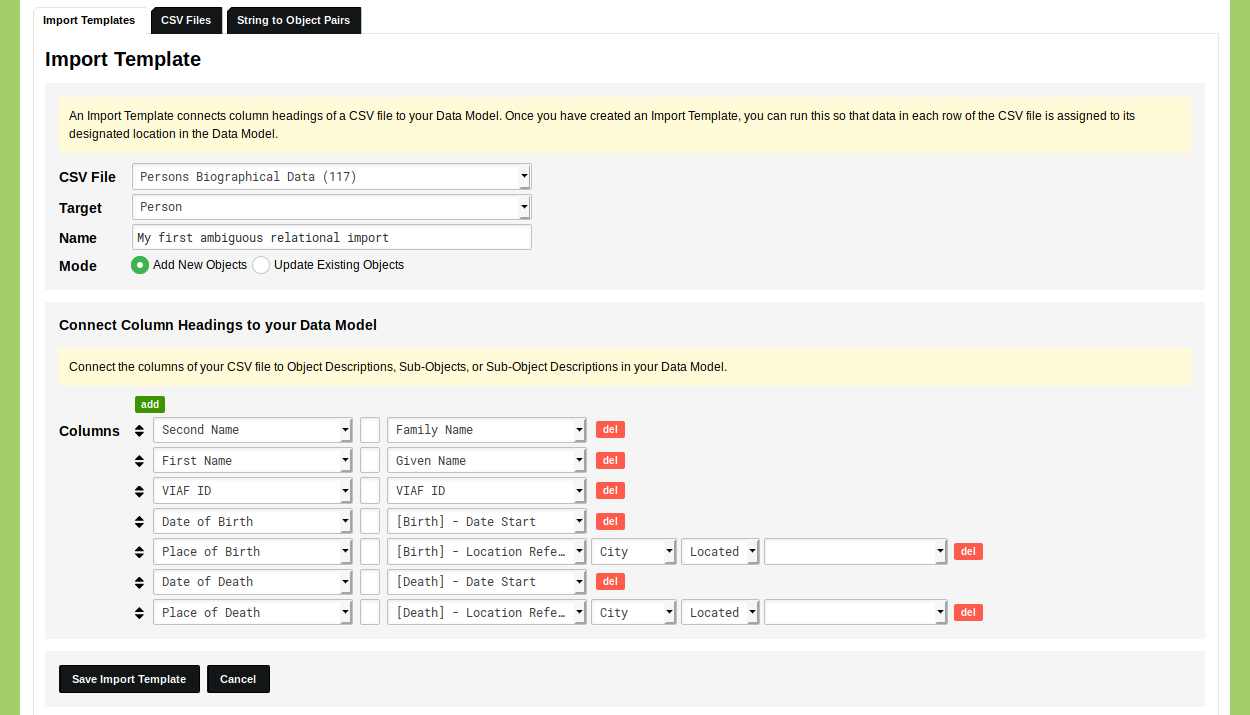
Click 'Save Import Template'. The Import Template is now listed in your overview of Import Templates. Click the green 'run' button on the right side of this overview to run the Import Template. Select the CSV file you want to use and inspect the displayed fields to see whether everything has been configured correctly. If everything is correct, click 'Next' to run the Import Template.
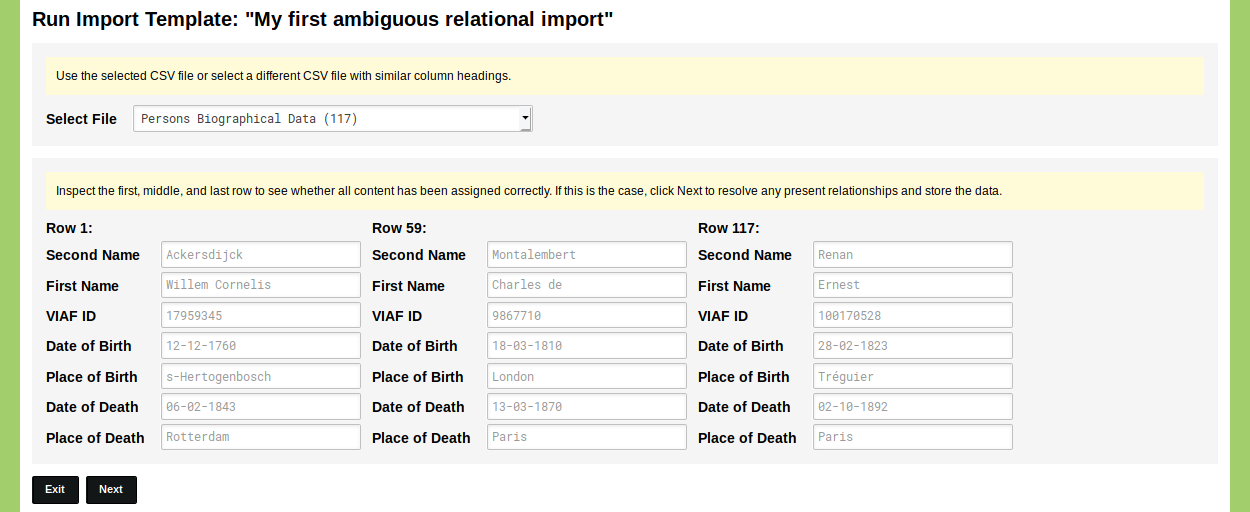
The Import Template will now connect the strings in this CSV file to the Objects in your nodegoat environment. Depending on the size of the CSV file and the amount of Objects this can take seconds or several minutes. The blue status bars update you on the progress. Once all strings are processed, the results are shown. If any ambiguous data is found, the Import Template will ask you to make a choice based on the data in your CSV file.
In this case we are importing 117 Objects of people that all have a place of birth and a place of death, so we have a total of 234 strings. The import process first checks whether there are any duplicates and whether these strings have been stored before as a 'String to Object Pair' (during another import process). Here 126 new strings in the Type 'City' are found. These are checked against the Objects in this Type. Of the 126 strings, 66 have an unambiguous match: strings like 'Wiepersdorf' and 'Deventer' match with only one Object in the Type 'City'. The remaining 60 strings have more than one, or no match in the Type 'City'. These have to be disambiguated by hand:
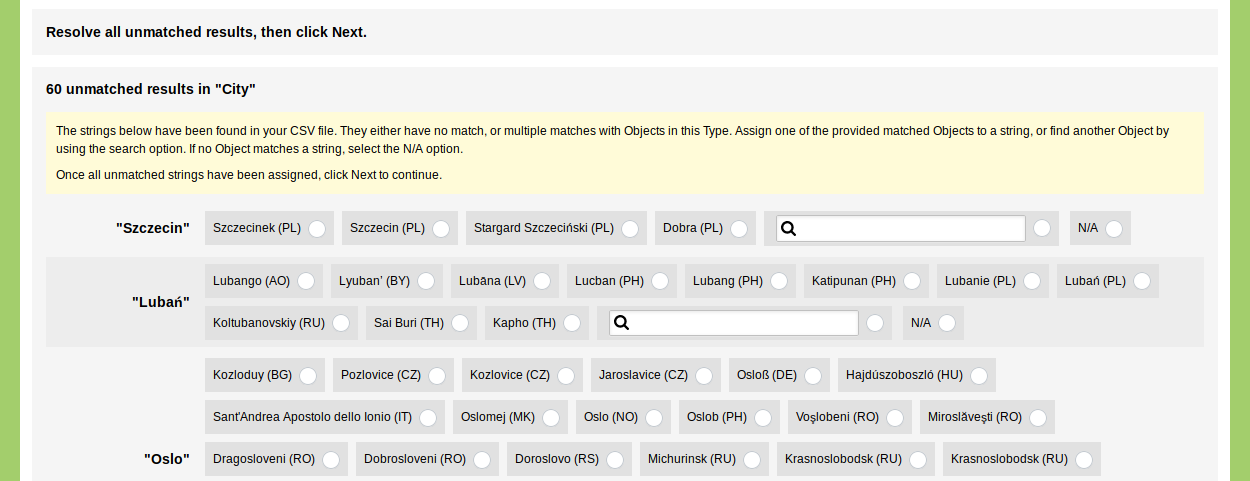
The string 'Szczecin' matches with four Objects: 'Szczecinek (PL)', 'Szczecin (PL)', 'Stargard Szczeciński (PL)', and 'Dobra (PL)'. Click on the name of an Object to inspect the Object. By clicking on the name of the Object 'Dobra (PL)' you see that in the list of alternate names 'Szczecinska' is listed, which is the reason why this Object matched with the string 'Szczecin'. In this case the Object 'Szczecin (PL)' is the correct match: click on the circular button next to the name of the Object to assign this Object to the string 'Szczecin'.
If none of the presented results is applicable, you can use the search option to find an Object that you want to match. If no match is available, use the 'N/A' option to assign no Object to this string.
You will see that some of these terms are almost impossible to disambiguate without a good understanding of the dataset. For the purpose of the Guide it is not important whether you select the correct 'Woodstock' out of the 11 possible places called 'Woodstock'. This is just to highlight how important it is to have clean data if possible, and how complicated dealing with non-disambiguated data can become.
After you have assigned all the strings to Objects, click 'Next'. Once the import process is done, click 'Exit' and navigate to the tab 'String to Object Pairs'. There you see connections that have been made between the strings in your CSV files and Objects in your nodegoat environment. If these are incorrect or outdated, you can remove them.
Navigate to the Data section of your nodegoat environment to inspect the result of your import process.