Ingest Transcription Data from Transkribus
In this guide we will ingest data from Transkribus. The configuration that will be implemented in this guide will allow you to ingest multiple documents of a single collection. You can reduce the complexity by changing the configuration to a single document, or you can expand the complexity by targeting multiple collections. You can decide to include a link to the image of a page, or skip this step.
Once the Ingestion Processes have run, you can use the ingested data as reference material in your nodegoat projects or use the data as primary sources and text tag mentioned people, places, or any other kind of information. Follow the guides 'Add Source References' or 'Text Tagging' to learn more about this.
Model
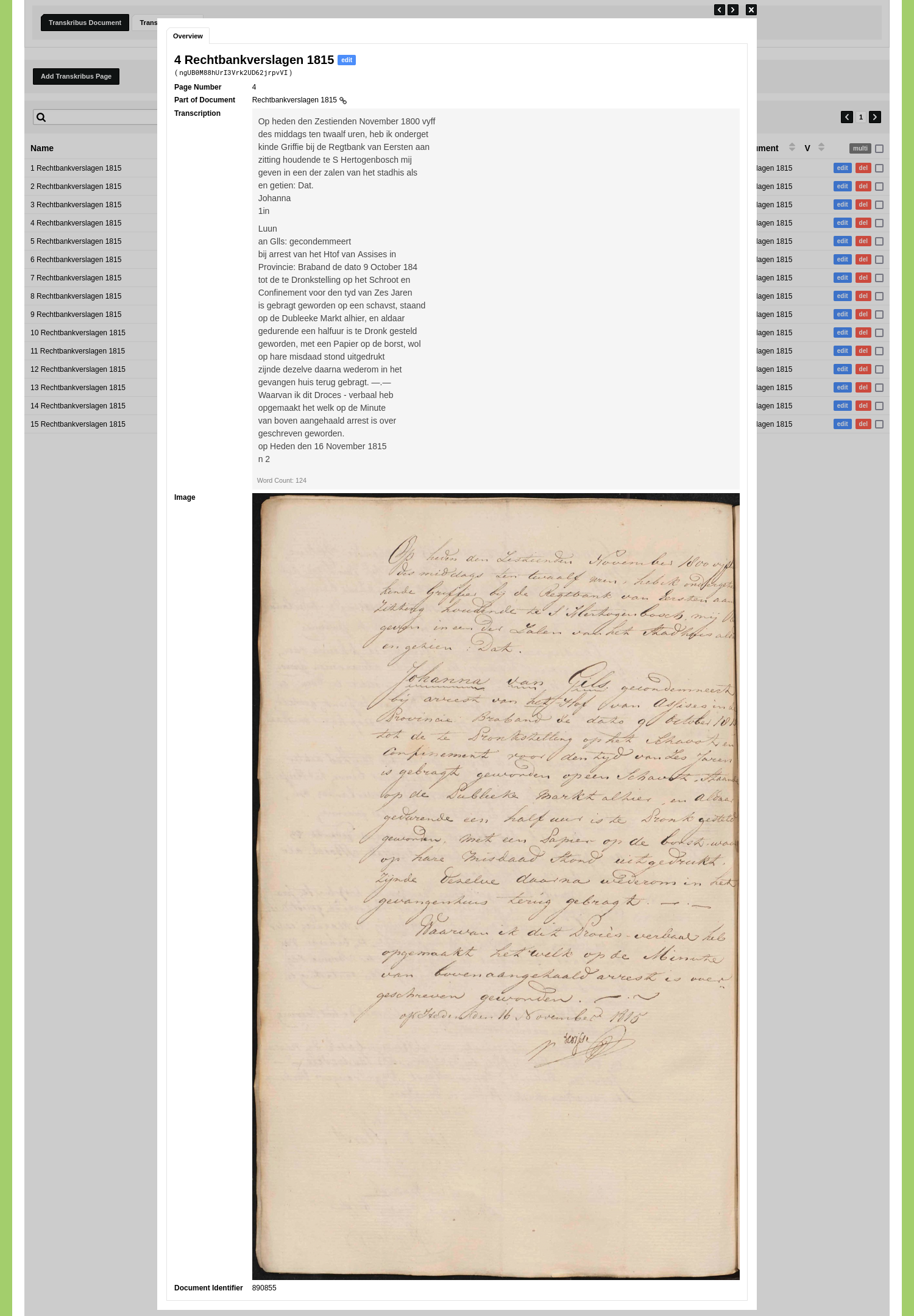
To store these transcriptions we need to add two new Object Types: 'Transkribus Document' and 'Transkribus Page'. Go to Model and go to the tab 'Object Types'. Click 'Add Object Type'. Enter the name of the first Object Type in the 'Name' field: 'Transkribus Document'.
Leave the 'Fixed Field' option for the Object Name checked so you can use a single input field for Object Names.
Specify an Object Description with the name 'Identifier' to be able to store an identifier for each document. Keep the value type of this Object Description set to 'String'. Check the checkbox 'Quick Search' and 'Overview'. Read the guide on creating your first Object Type to learn more about these settings.
Click 'Save Type' to save your Object Type. Click 'Add Object Type' once more. Enter the name of the second Object Type in the 'Name' field: 'Transkribus Page'.
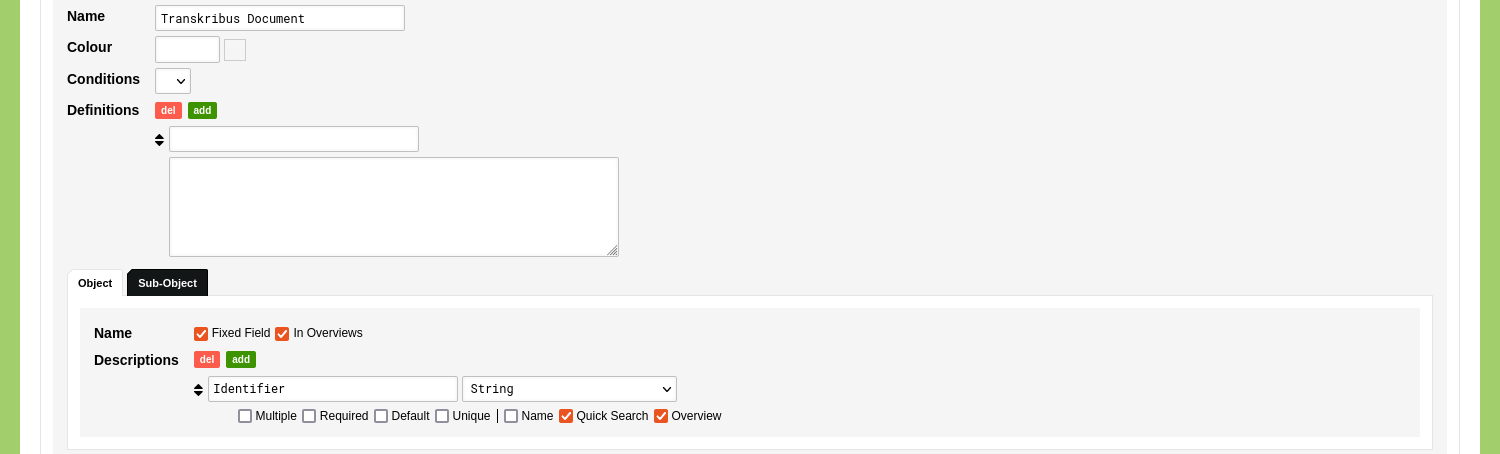
Uncheck the 'Fixed Field' and 'In Overviews' options for the Object Name, as we will generate the Object Name based on Object Descriptions.
Specify four Object Description and name them 'Page Number', 'Part of Document', 'Transcription', 'Image', and 'Document Identifier'. Set the value type of the 'Page Number' Object Description to 'Number' and set the value type of 'Author' to 'Reference: Object Type' and select 'Document'. Set the value type of the 'Transcription' Object Description to 'Text (Tags & Layout)' (and check the 'Marginalia' option), set the value type of 'Image' to 'Media (External)', and set the value type of 'Document Identifier' to 'String'. Check the 'Name', 'Quick Search' and 'Overview' options for the 'Page Number', 'Part of Document' Object Descriptions. Check the 'Quick Search' option for the 'Transcription' Object Description.
Click 'Save Object Type'.
Go to Management and select 'Projects'. Add a new project, or edit an existing one, in order to be able to work with these new Object Types. Enable the newly created Object Types in your project.
Go to the Data section of your environment and select the Object Types you just made to check if everything has been configured correctly. Click 'Add Transkribus Document' and 'Add Transkribus Page' to open the data entry form and verify that the fields that will host the new data are present.
Linked Data Resource
To learn more about how you can query your Transkribus data via the Transkribus REST API you can read the documentation. As you can see in the documentation, your data can be accessed via the following requests: 'https://transkribus.eu/TrpServer/rest/collections/list' will return you collections, 'https://transkribus.eu/TrpServer/rest/collections/COLLECTION-ID/list' will return the documents of one collection, 'https://transkribus.eu/TrpServer/rest/collections/COLLECTION-ID/DOCUMENT-ID/fulldoc' will return the pages of one document and 'https://transkribus.eu/TrpServer/rest/collections/COLLECTION-ID/DOCUMENT-ID/PAGE-NR/text' will return the transcription of one page.
This guide will show how to request the documents and pages within one collection. The request 'https://transkribus.eu/TrpServer/rest/collections/COLLECTION-ID/list' will produce a list all the documents in this collection. 'https://transkribus.eu/TrpServer/rest/collections/COLLECTION-ID/DOCUMENT-ID/fulldoc' will give us all the pages, and 'https://transkribus.eu/TrpServer/rest/collections/COLLECTION-ID/DOCUMENT-ID/PAGE-NR/text' will update these pages with the transcription data.
Authentication
The first part of the documentation covers the way how you can authenticate your user. To do this, you need to post your credentials to this endpoint: 'https://transkribus.eu/TrpServer/rest/auth/login'. This can be done by using the cURL command-line tool. In case you are unfamiliar with command-line interfaces, you can read more about this in the Programming Historian Lesson 'Introduction to the Bash Command Line'.
Open a command-line interpreter by looking for 'Terminal' in a Linux or MacOS based operating system. In a Windows based operating system you can look for 'CMD' to open Command Prompt. You paste the following command in the command-line interpreter:
curl https://transkribus.eu/TrpServer/rest/auth/login -d "user=YOURUSERNAME&pw=YOURPASSWORD"This will return an XML document that contains the user profile. Find the 'sessionId' element and copy its content. This numerical identifier will be used in subsequent requests. The session is valid for a limited amount of time. If you request returns an error, run the authentication command again and update the session ID in your requests.
Documents
Go to Model and go to 'Linked Data'. Click 'Add Linked Data Resource' and give the resource a name like 'Transkribus Documents'. Enter the request URL 'https://transkribus.eu/TrpServer/rest/collections/' in the 'URL' input field and enter '?JSESSIONID=YOURSESSIONID&format=xml' in the 'URL Options'. Leave the 'URL Headers' empty.

You can use these settings to select the Transkribus Collection you want to use. Do this by entering list in the 'Query' input field and click the green 'test' button. Find the collection of your choice in the response and copy the value of the 'colId' element, e.g. '132648'. Paste this into the Query input field followed by '/list', e.g. 132648/list. Click the green 'test' button again to get a response with the documents of the selected collection.
Click the green 'use' button to populate the mapping options. Select the position in the returned data that contains the URI and Label. To do this, change the dropdown menu next to the label 'URI' to: {"[]":{"docId":""}} and change the dropdown menu next to the label 'Label' to: {"[]":{"title":""}}.
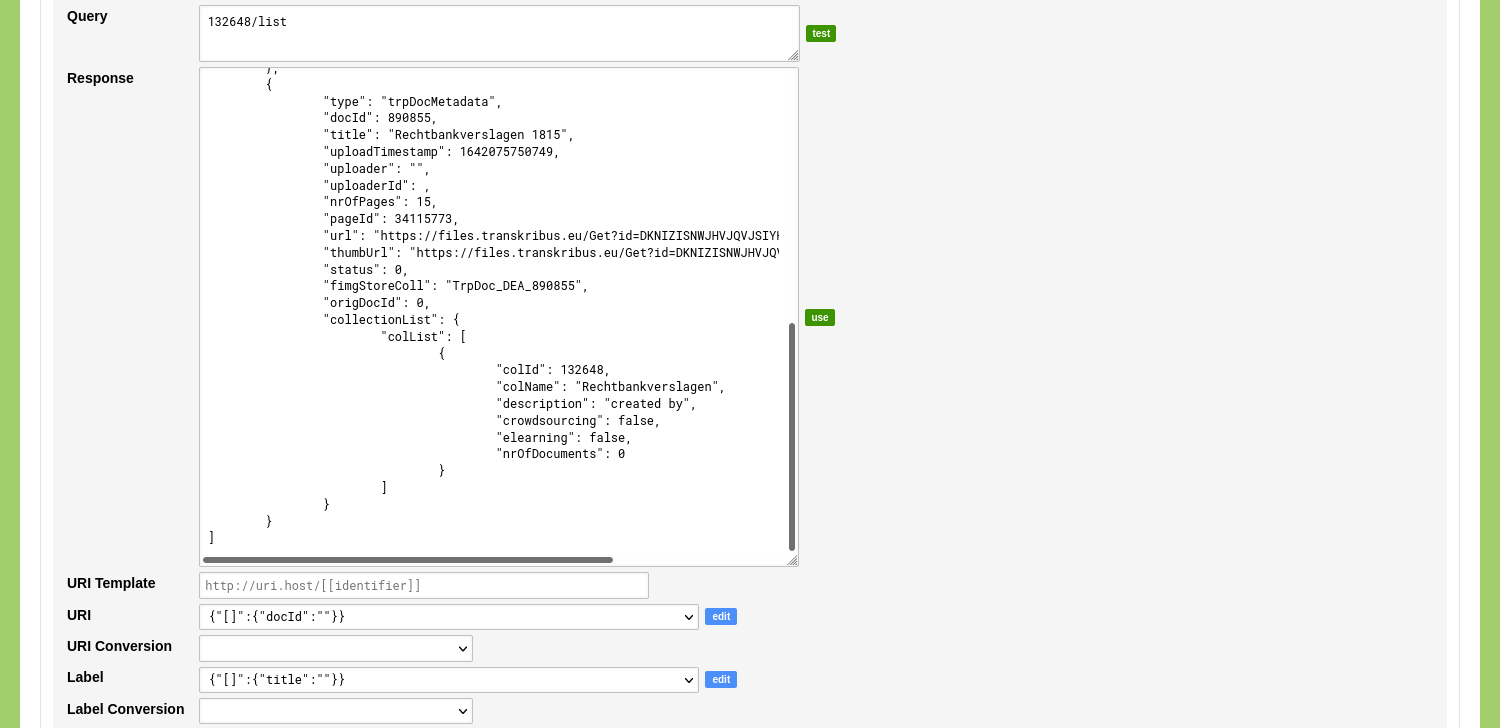
Click 'Save Linked Data Resource' to store this configuration.
Pages
Create a new Linked Data Resource 'Transkribus Pages'. Enter the request URL 'https://transkribus.eu/TrpServer/rest/collections/' in the 'URL' input field and enter '?JSESSIONID=YOURSESSIONID' in the 'URL Options'. Leave the 'URL Headers' empty.
As you have seen above, the request to fetch the pages looks like this: 'https://transkribus.eu/TrpServer/rest/collections/COLLECTION-ID/DOCUMENT-ID/fulldoc'. The first part of this request has been entered in the 'URL' input field. We will configure the second part in the 'Query' input field, i.e. '132648/888738/fulldoc'. The first identifier refers to a collection, the second identifier refers to a document. You can retrieve both identifiers by copying them from the response of the 'Transkribus Documents' Linked Data Resource.
To be able to ingest pages of multiple documents, we need to be able to update the identifiers of the document. The Guides 'Ingest External Identifiers' and 'Ingest Publication Data' describe in depth how variables in queries can be defined.
Enter a query and variable tag around the document identifier so the Ingestion Process is able to update this for every query. Enter this in the 'Query' input field:
132648/[query=document][variable=id]888738[/variable][/query]/fulldocClick the green 'test' button to run the query. This action will combine the values in the 'URL' field, the 'URL options' field and the 'Query' field.
After the query has run, the results are shown in the 'Response' input field. This field allows you to inspect the results and to verify that all specified variables have been returned. By clicking the green 'use' button, the returned data populates the mapping options.
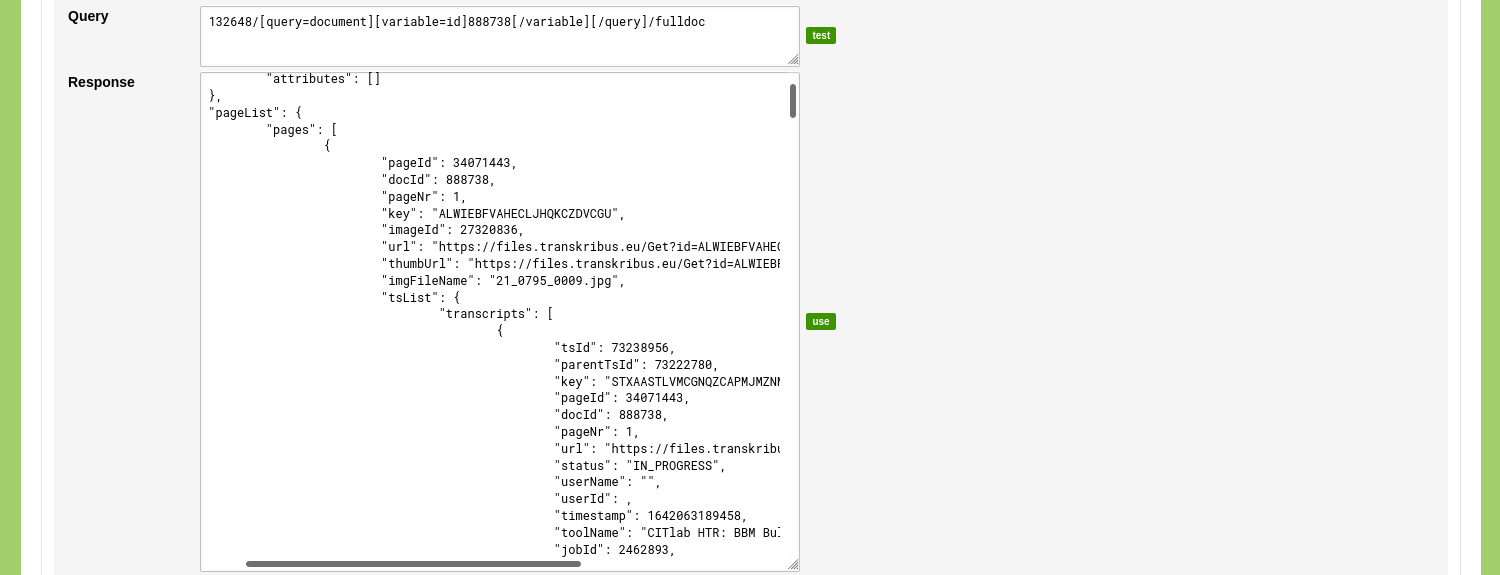
Select the position in the returned data that contains the URI and Label. To do this, change the dropdown menu next to the label 'URI' to: {"pageList":{"pages":{"[]":{"pageId":""}}}} and change the dropdown menu next to the label 'Label' to: {"pageList":{"pages":{"[]":{"pageNr":""}}}}.
To process the URL of the image and the document identifier that we need to obtain the transcription data we add two custom key/value pairs. Click the green 'add' button next to the 'Values' label once. Enter the name for the first key: 'Image'. Change the dropdown menu for this value to: {"pageList":{"pages":{"[]":{"key":""}}}}. Enter the name for the second key: 'Docuement ID'. Change the dropdown menu for this value to: {"pageList":{"pages":{"[]":{"docId":""}}}}.
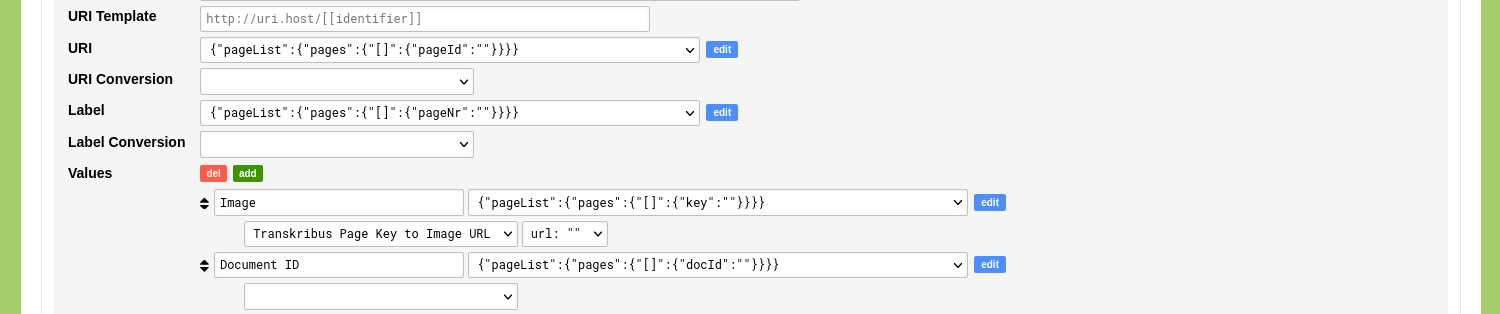
Click 'Save Linked Data Resource' to store this configuration.
In the currently stored configuration, the Image value consists of the 'Key' of the Transkribus image (e.g. 'ALWIEBFVAHECLJHQKCZDVCGU'). To obtain a visual representation, we need to change this value into 'https://files.transkribus.eu/iiif/2/ALWIEBFVAHECLJHQKCZDVCGU/full/1500,/0/default.jpg'. To do this, we can run a 'Linked Data Conversion' script on the value that will be ingested.
Go to the tab 'Conversions' and click 'Add Linked Data Conversion'. Enter a name like 'Transkribus Page Key to Image URL' and a description of the script. Enter the input data in the 'INPUT =' input field: ALWIEBFVAHECLJHQKCZDVCGU. Enter the following JavaScript code in the 'Script' input field.
const key = INPUT;
const url = 'https://files.transkribus.eu/iiif/2/' + key + '/full/1500,/0/default.jpg'
OUTPUT = {url: url}This scripts renders a URL based on the provided key value. Click the green 'test' button to test this script.
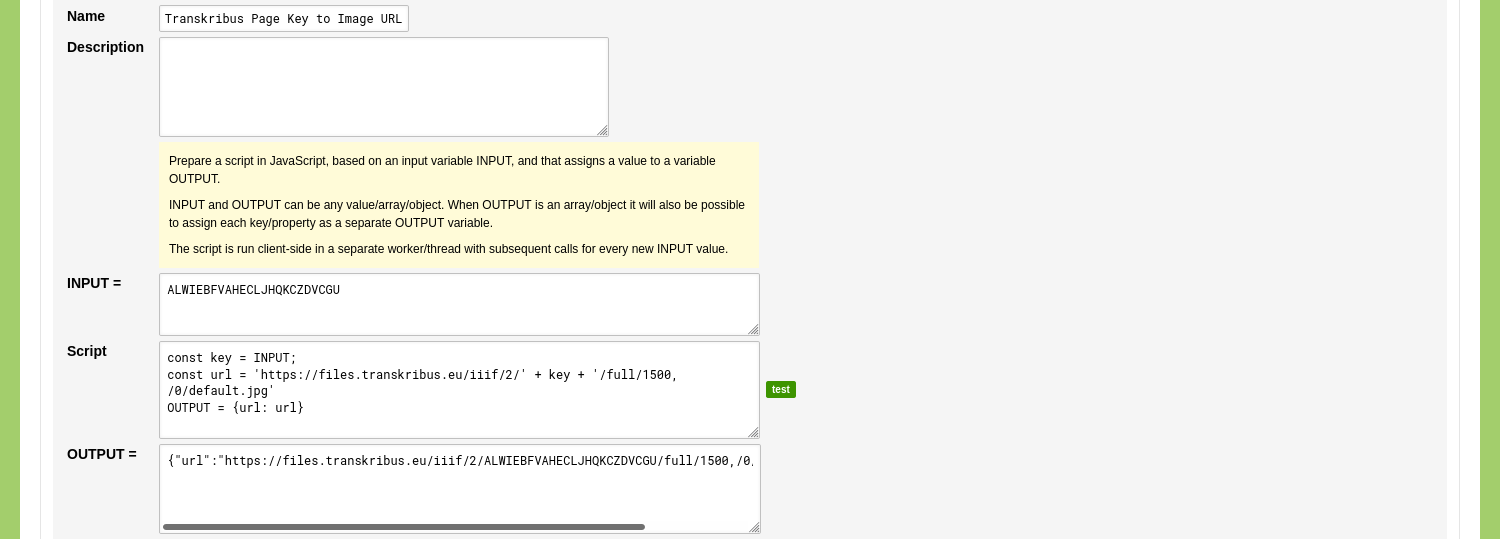
If the output is correct you can click 'Save Linked Data Conversion'.
Go to the tab 'Resources' and click the blue 'edit' button at the resource 'Transkribus Pages'. Scroll down to the custom key/value pairs and select the newly created Linked Data Conversion scripts as well as the generated output in the dropdown menus shown below the 'Image' value.
Click 'Save Linked Data Resource' to store this configuration.
Transcriptions
Create a new Linked Data Resource 'Transkribus Page Text'. Enter the request URL 'https://transkribus.eu/TrpServer/rest/collections/' in the 'URL' input field and enter '?JSESSIONID=YOURSESSIONID' in the 'URL Options'. Leave the 'URL Headers' empty.
As you have seen above, the request to fetch the transcription data looks like this: 'https://transkribus.eu/TrpServer/rest/collections/COLLECTION-ID/DOCUMENT-ID/PAGE-NR/text'. The first part of this request has been entered in the 'URL' input field. We will configure the second part in the 'Query' input field, i.e. '132648/888738/1/text'. The first identifier refers to a collection, the second identifier refers to a document, the third number refers to the page number. You can retrieve the two identifiers by copying them from the response of the 'Transkribus Documents' Linked Data Resource.
To be able to ingest pages of multiple documents, we need to be able to update the identifiers of the document. Enter a query and variable tag around the document identifier and the page number so the Ingestion Process is able to update these values for every query. Enter this in the 'Query' input field:
132648/[query=document][variable=id]890855[/variable][/query]/[query=page][variable=nr]1[/variable][/query]/textClick the green 'test' button to run the query. This action will combine the values in the 'URL' field, the 'URL options' field and the 'Query' field.
After the query has run, the results are shown in the 'Response' input field. This field allows you to inspect the results and to verify that all specified variables have been returned. By clicking the green 'use' button, the returned data populates the mapping options.
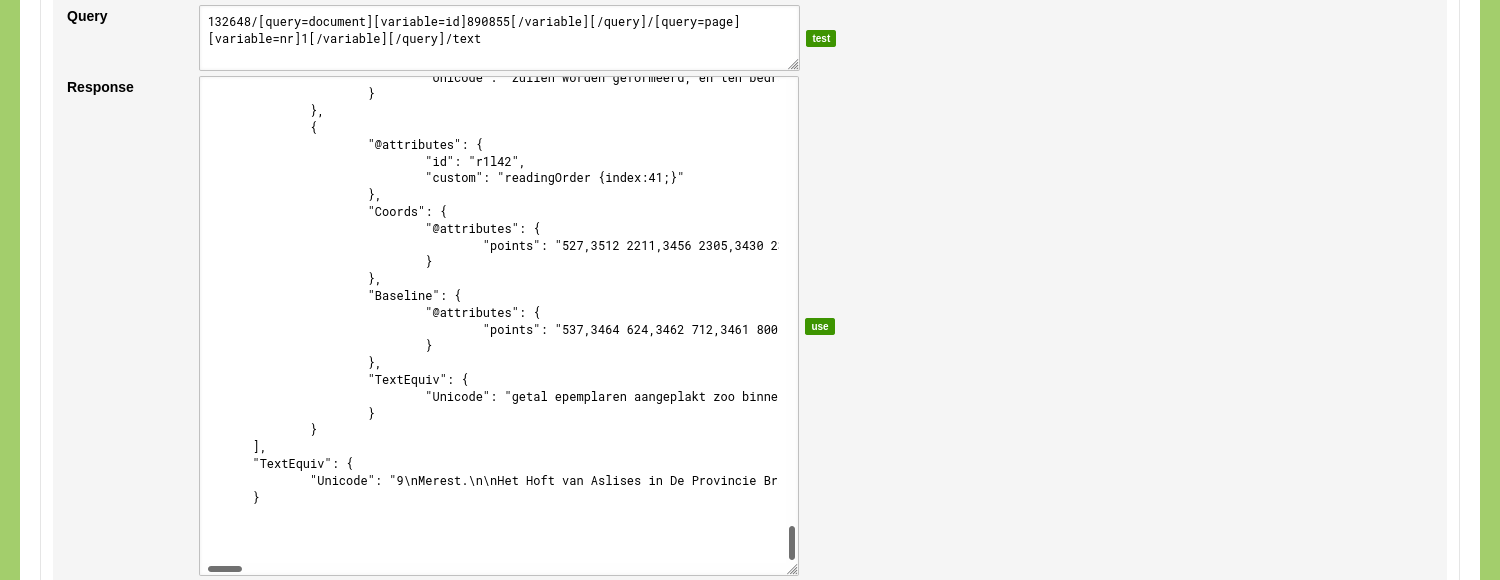
Select the position in the returned data that contains the URI and Label. To do this, change the dropdown menu next to the label 'URI' to: {"PcGts":{"Page":{"@attributes":{"imageFilename":""}}}} and change the dropdown menu next to the label 'Label' to: {"PcGts":{"Page":{"@attributes":{"imageFilename":""}}}}. As this query does not return a URI or label, we use the imageFilename as a placeholder.
To process the transcribed text of the page we add a custom key/value pair. Enter the name for the key: 'Transcription'. Change the dropdown menu for this value to: {"PcGts":{"Page":{"TextRegion":{"TextEquiv":{"Unicode":""}}}}}.

This configuration works for pages that have a single region of texts. If multiple regions on a page are identified, you need to collect the transcribed data of each region into a single value. To do this, you specify a Resource Path. Change the value {"PcGts":{"Page":{"TextRegion":{"TextEquiv":{"Unicode":""}}}}} into {"PcGts":{"Page":{"TextRegion":{"[*]TextLine":{"[]":{"TextEquiv":{"Unicode":""}}}, "<":"join:\n"}}}}. This path will iterate over any 'TextLine' element and will join all the 'Unicode' values into a single value with a newline character as separator.
Click 'Save Linked Data Resource' to store this configuration.
Ingestion Processes
You are now ready to configure the Ingestion Processes. Enable these processes by going to Management and select 'Projects'. Edit your project and enable the System Process 'Ingestion'.
Documents
Go to the Data section of your environment. Go to the tab 'Processes', click 'Ingestion', and click 'Add Ingestion'.
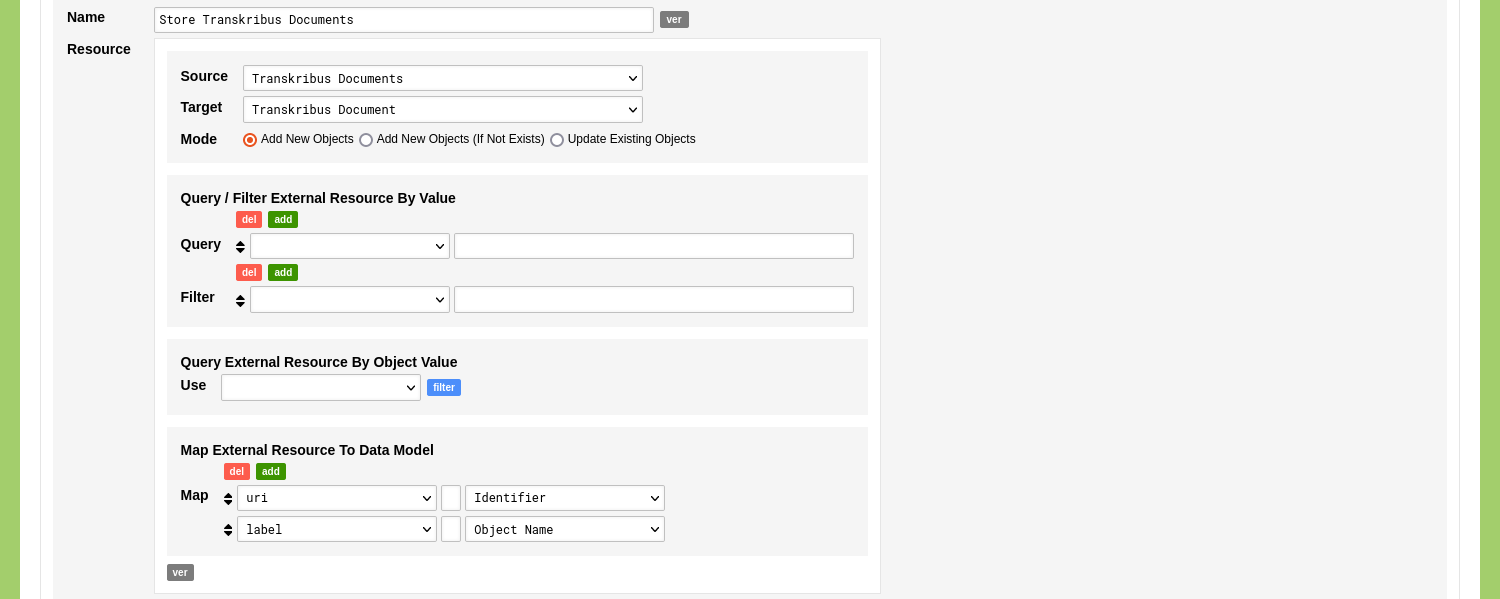
Give the Ingestion Process a name like 'Store Transkribus Documents'. Use the dropdown menu with the label 'Source' to select the Linked Data Resource 'Transkribus Documents'. Use the dropdown menu with the label 'Target' to select the Object Type 'Transkribus Document'. Since we are adding new Objects you can leave the mode of the Ingestion Process to 'Add New Objects'.
Because the query in the Linked Data Resource has no interactive elements, you can disregard the form sections 'Query / Filter External Resource By Value' and 'Query External Resource By Object Value'.
Use the form section 'Map External Resource To Data Model' to connect the returned variables to elements in the selected Object Type. In this case you connect the variable 'URI' to the Object Description 'Identifier'. You connect the variable 'Label' to the Object Name.
Click 'Save Ingestion'.
You now see the newly created Ingestion Process listed in your overview of Ingestion Processes. Click the green 'run' button on the right side of this overview to run this Ingestion Process.
Click 'Run Ingestion' to run the Ingestion Process. The Ingestion Process runs and informs you about the results. If everything went correctly you now have ingested new Objects of the Type 'Transkribus Document'. Open the Type 'Transkribus Document' to see the newly ingested Objects.
Pages
Go to the Data section of your environment. Go to the tab 'Processes', click 'Ingestion', and click 'Add Ingestion'.
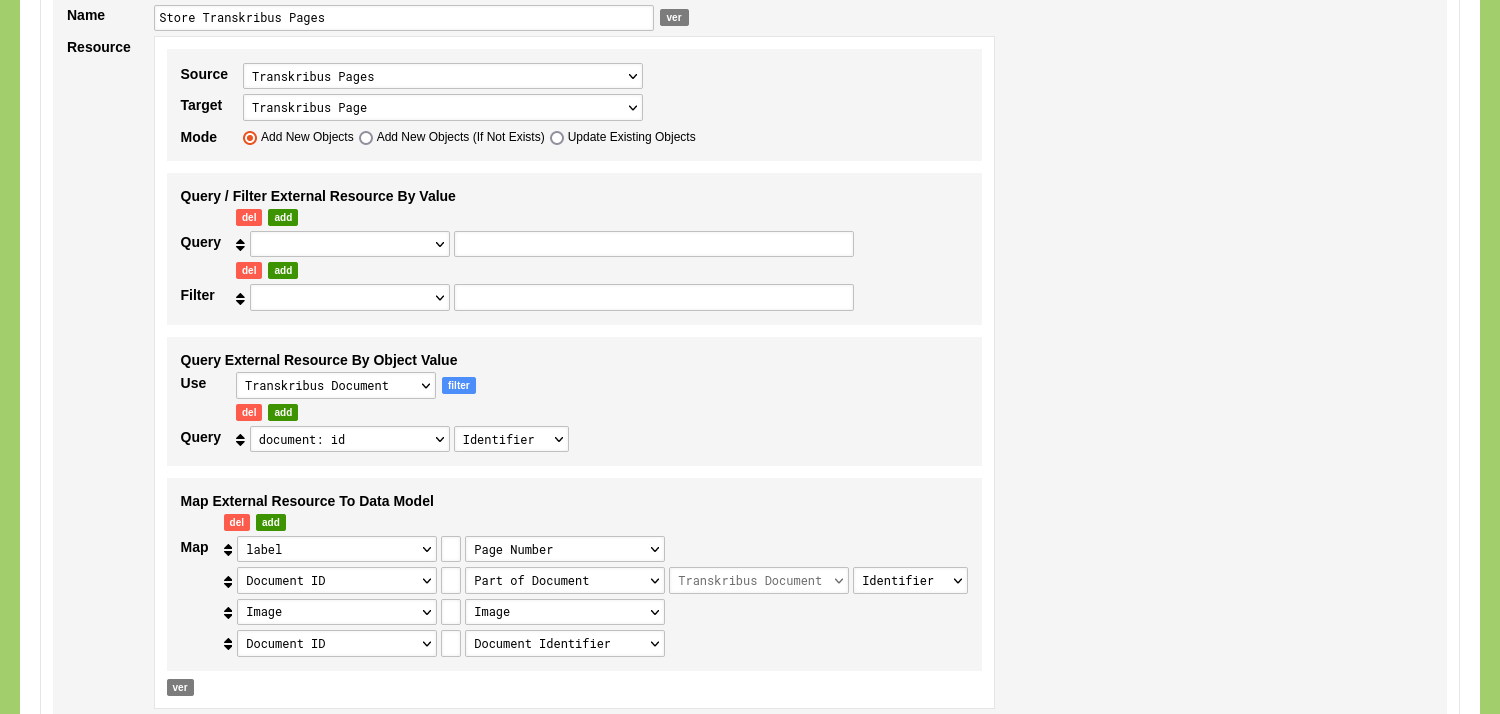
Give the Ingestion Process a name like 'Store Transkribus Pages'. Use the dropdown menu with the label 'Source' to select the Linked Data Resource 'Transkribus Pages'. Use the dropdown menu with the label 'Target' to select the Object Type 'Transkribus Page'. Since we are adding new Objects you can leave the mode of the Ingestion Process to 'Add New Objects'.
Disregard the form section 'Query / Filter External Resource By Value'.
We want to run the query for every Object of the Type 'Transkribus Document' and assign the Document identifier to the previously defined variable 'document: id'. To configure this, select the Object Type 'Transkribus Document' next to the label 'Use' in the form section 'Query External Resource By Object Value'. Use the first dropdown menu next to label 'Query' to select the variable 'document: id' and use the second dropdown menu to select the Object Description 'Identifier'. With these settings in place, the Ingestion Process will run a query for every Object of the Type 'Transkribus Document' and will assign the value of the 'Identifier' Object Description (e.g. '888738') to the variable 'document: id'.
Use the form section 'Map External Resource To Data Model' to connect the returned variables to elements in the selected Object Type 'Publication'. In this case you connect the variable 'label' to the Object Description 'Page Number'. You connect the variable 'Document ID' to the Object Description 'Part of Document'. The referenced Object Type 'Transkribus Document' appears and you can use the dropdown menu 'Element that will be used to make a Reference. If left blank, Quicksearch Descriptions will be used.' to select the 'Identifier' Object Description. You connect the variable 'Image' to the Object Description 'Image'. Click the green 'add' button to add an additional set of options. Select the variable 'Document ID' once more and connect this to the Object Description 'Document Identifier'.
With these settings in place, the Ingestion Process will run a query for every Object of the Type 'Transkribus Document' and will add the returned data to the Object Type 'Transkribus Page'.
Click 'Save Ingestion'.
You now see the newly created Ingestion Process listed in your overview of Ingestion Processes. Click the green 'run' button on the right side of this overview to run this Ingestion Process.
Click 'Run Ingestion' to run the Ingestion Process. The Ingestion Process runs and informs you about the results. If everything went correctly you now have ingested new Objects of the Type 'Transkribus Page'. Open the Type 'Transkribus Page' to see the newly ingested Objects.
Transcriptions
Go to the Data section of your environment. Go to the tab 'Processes', click 'Ingestion', and click 'Add Ingestion'.
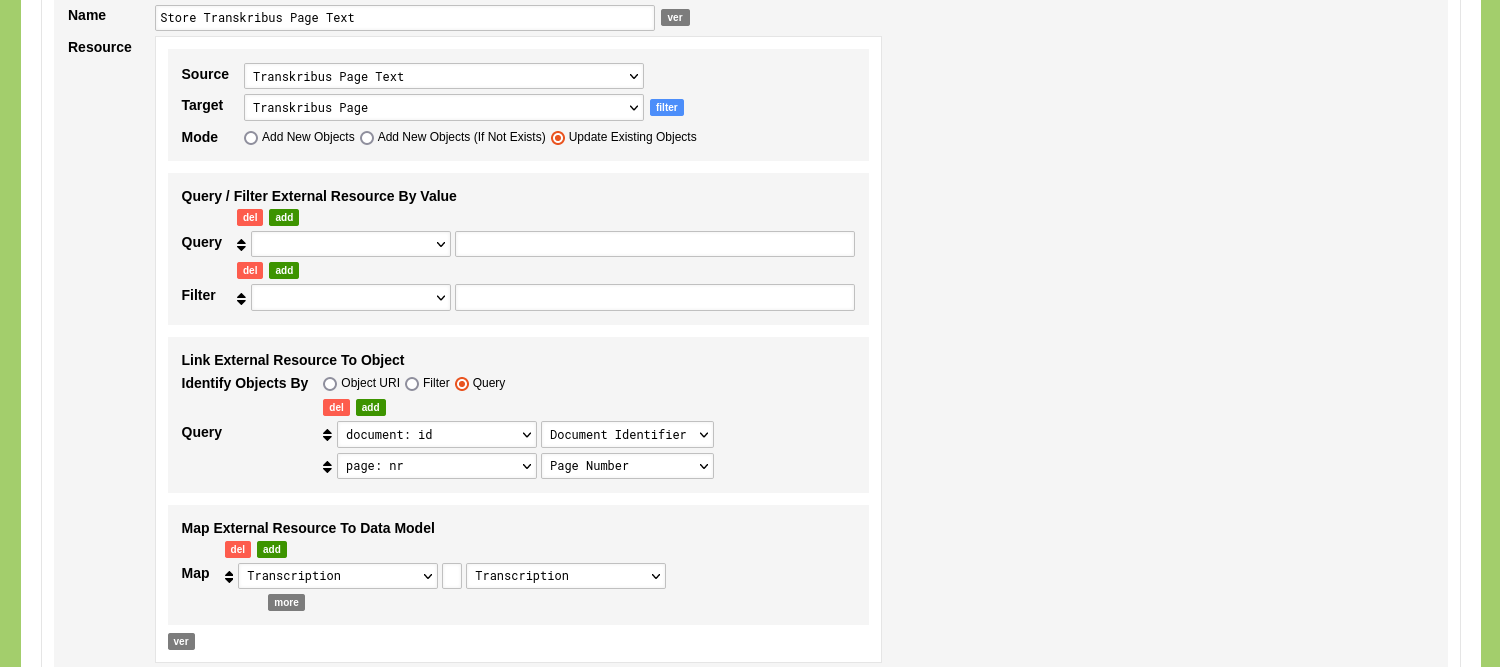
Give the Ingestion Process a name like 'Store Transkribus Page Text'. Use the dropdown menu with the label 'Source' to select the Linked Data Resource 'Transkribus Page Text'. Use the dropdown menu with the label 'Target' to select the Object Type 'Transkribus Page'. This process will update the previously ingested Objects, so change the mode to 'Update Existing Objects'.
Disregard the 'Query / Filter External Resource By Value' form section.
Use the form section 'Link External Resource To Object' to establish a link between the returned data and the data already present in your nodegoat environment. Set 'Identify Objects By' to 'Query' and use the first dropdown menu ('Variable in the Linked Data query.') to select the variable 'document: id'. Use the second dropdown menu ('Target Element in Data Model.') to select the 'Document Identifier' Object Description. Click the green 'add' button to add an additional set of options: use the first dropdown menu to select the variable 'page: nr'. Use the second dropdown menu to select the 'Page Number'. With these settings in place, the Ingestion Process will run a query for every Object of the Type 'Transkribus Page' and will assign the value of the 'Document Identifier' Object Description (e.g. '888738') to the variable 'document: id' and the value of the 'Page Number' Object Description (e.g. '1') to the variable 'page: number'.
Use the form section 'Map External Resource To Data Model' to connect the returned variables to elements in the selected Object Type. In this case you connect the variable 'Transcription' to the Object Description 'Transcription'.
Set 'uri' and 'label' to empty values and use the red 'del' button to remove them.
With these settings in place, the Ingestion Process will run a query for every Object of the Type 'Transkribus Page' and will update the Object with the returned transcription data.
Click 'Save Ingestion'.
You now see the newly created Ingestion Process listed in your overview of Ingestion Processes. Click the green 'run' button on the right side of this overview to run this Ingestion Process.
Click 'Run Ingestion' to run the Ingestion Process. The Ingestion Process runs and informs you about the results. If everything went correctly you now have updated the Object of the Type 'Transkribus Page'. Open the Type 'Transkribus Page' to see the updated Objects.