Reconcile Named Entities
The guide 'Reconcile Textual Data' describes how you can reconcile any kind of textual data against any dataset in your nodegoat environment based on pattern matching.
This guide will show how to reconcile a subset of identified entities (e.g. places, or people) in textual data against a dataset in your nodegoat environment. Such a Reconciliation Process can be run on textual data that has been pre-processed in a Natural Language Processing (NLP) workflow. Use a Named Entity Recognition (NER) algorithm to identify entities and store the results as tags (e.g. [entity=place]Den Haag[/entity]) in the textual data in nodegoat. For example:
უფროსი თვითონ შეირთო, [entity=person]შვათან[/entity] შერთო ხელმწიფის შვილს
და უმცროსი [entity=person]მოსამსა ხურის[/entity] შვილს.
მერე ის დაბრუნდა თავის [entity=place]სახელმწიფოში[/entity].
გზაზედ გადიარა ერთ მდევების სახელმწიფოზე.You can configure the Reconciliation Process to only use parts of the text that are enclosed by a specific entity tag. This allows you, for example, to only reconcile places, or to only reconcile persons.
To do this, go to Data and go to the Object Type that contains the textual data. Click the icon in the toolbar in the right top corner of your environment. This opens the 'Conditions' dialog with which you can specify conditional formatting rules for Names, Descriptions and Nodes in visualisations.
Open the tab 'Descriptions' and select the Object Description that contains the textual data. Click the grey 'regex' button next to the label 'Regular Expression'. Enter a regular expression pattern that captures the tagged entity you want to target in your Reconciliation Process, for example:
(\[entity=place\])(.+?)(\[\/entity\])
and a corresponding template, for example:
$1[reconcile]$2[/reconcile]$3
This action enriches the targeted tag with a [reconcile] tag that will be used by a Reconciliation Process to identify which parts of a text should be reconciled.
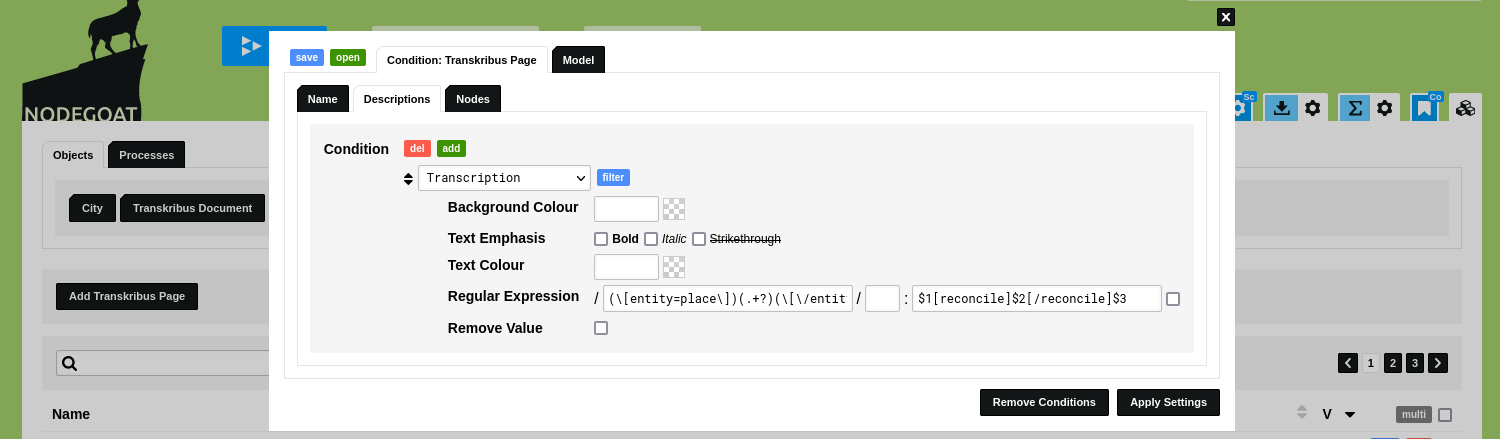
Click 'Apply Settings'.
Go to the tab 'Processes', click 'Reconciliation'. Click the icon in the toolbar in the right top corner of your environment to open the 'Conditions' dialog. Open the tab 'Model' and check the checkbox next to the Object Type that contains your textual data.

This applies the configured Condition to the selected Object Type during a run of the Reconciliation Process. Only those parts of the text that are enclosed by a [reconcile] will be used in the Reconciliation Process.
Appendix: Store Transkribus Tags in nodegoat
The guide 'Ingest Transcription Data from Transkribus' describes how you can ingest transcription data from Transkribus into nodegoat. To also ingest the tags that have been applied in the Transkribus environment to nodegoat, go to Model and go to 'Linked Data'. Go to the tab 'Conversions' and click 'Add Linked Data Conversion'. Enter a name like 'Parse Transkribus Tags'.
Enter an example of your own tagged transcription data in the INPUT= field, or this example output of the Transkribus API:
[
{},
{},
{"TextLine": [
{
"@attributes": {
"id": "r1l28",
"custom": "readingOrder {index:27;} organization {offset:0; length:6;} place {offset:33; length:6;} place {offset:40; length:6;}"
},
"TextEquiv": {
"Unicode": "Lehren sich bald in verschiedene Länder Europa's verbreiteten"
}
}
]
}
]Enter the following JavaScript code in the 'Script' input field.
let str_page_text = '';
const arr_lines = INPUT[2]['TextLine'];
arr_lines.forEach(function(arr_line) {
let str_line = arr_line['TextEquiv']['Unicode'];
let num_line_length = str_line.length;
const str_attributes = arr_line['@attributes']['custom'];
let arr_matches = str_attributes.matchAll(/([a-z]+) {offset:(\d+); length:(\d+);}/g);
let num_offset = 0;
for (const arr_match of arr_matches) {
const str_tag = arr_match[1];
const num_tag_length = str_tag.length;
const num_entity_offset = Number(arr_match[2]) + num_offset;
const num_entity_length = Number(arr_match[3]);
str_line = str_line.slice(0, num_entity_offset) + '[entity='+str_tag+']' + str_line.slice(num_entity_offset, num_line_length);
num_line_length = num_line_length + num_tag_length + 9;
str_line = str_line.slice(0, num_entity_offset + num_entity_length + num_tag_length + 9) + '[/entity]' + str_line.slice(num_entity_offset + num_entity_length + num_tag_length + 9, num_line_length);
num_offset = num_offset + num_tag_length + 18;
num_line_length = num_line_length + 9;
}
str_page_text = str_page_text + str_line + '\n';
});
OUTPUT = str_page_text;Click the green 'test' button to inspect the result in the OUTPUT= field. Click 'Save Linked Data Conversion'.
Go to the tab 'Resources' and click the blue 'edit' button at the Linked Data Resource that ingests the transcription data. Scroll down to the custom key/value pairs and select the newly created Linked Data Conversion script in the dropdown menu shown below the 'Transcription' value and change the value to {"Page":[]}.
Click 'Save Linked Data Resource' to store this configuration. If you now use this Linked Data Resource in an Ingestion Process, the tags will be stored in the textual data. These tags can be targeted by setting a regular expression in the Conditions during a run of a Reconcilation Process.