Repertorium Academicum Germanicum - The Graduate Scholars of the Holy Roman Empire
CORE Admin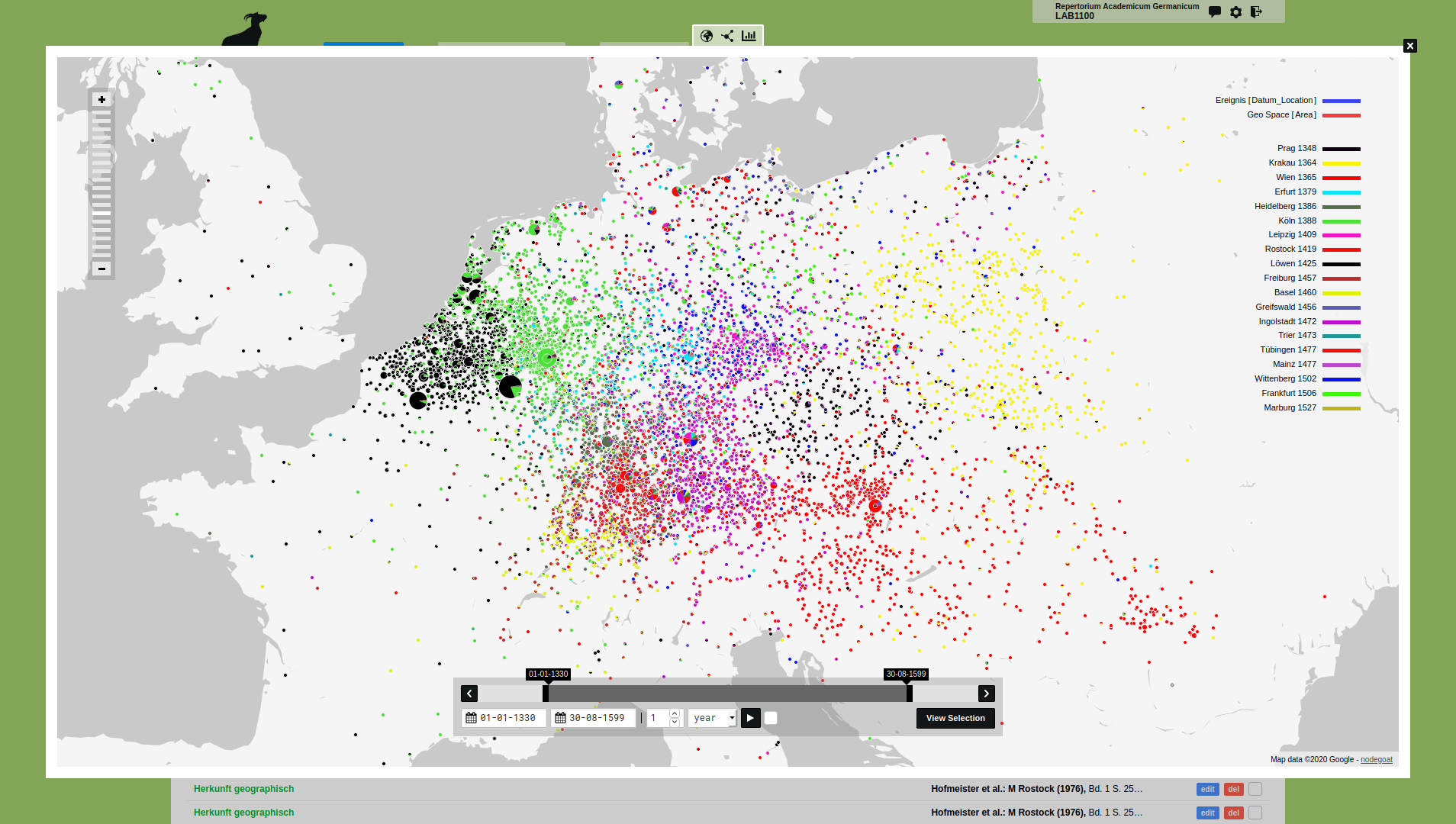
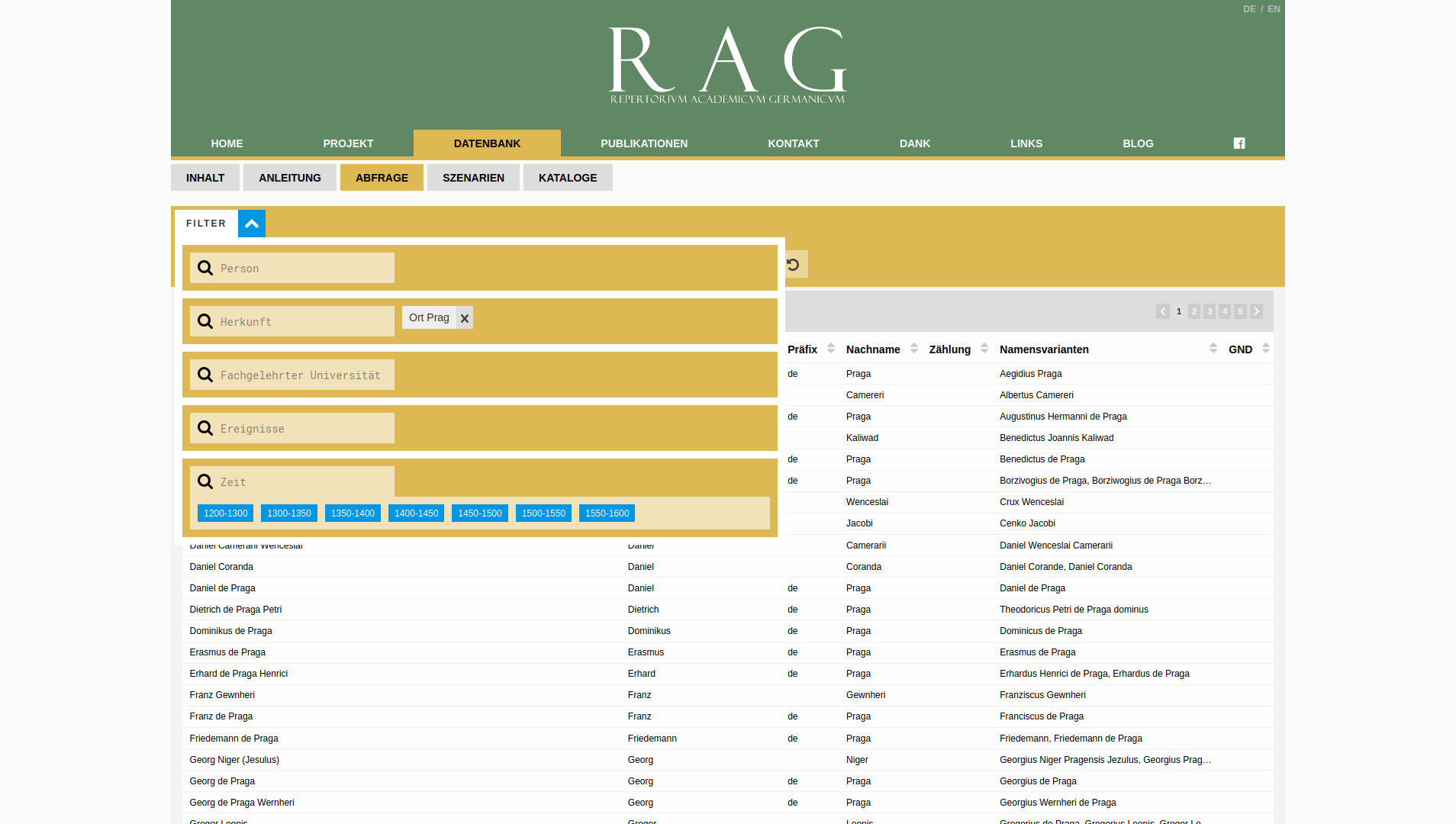
The aim of the Repertorium Academicum Germanicum (RAG) is to develop the history of the cultural reach of a pre-modern intellectual leadership. The RAG gains a comprehensive insight into the medieval origins of the modern knowledge society with around 60.000 scholars with 360.000 observations on their life and career paths, within the framework of an analysis of contextualized prosopography. The RAG uses nodegoat as their primary data storage application and research environment. nodegoat is also used to create and publish diachronic geographical and social visualisations.
Work on the RAG began in 2001 under the direction of Rainer Schwinges and Peter Moraw, financed by the Swiss National Science Foundation (SNSF), the German research foundation and the Fritz Thyssen Foundation. From 2007 to 2019 the project was funded by the Union of the German Academies of Sciences and Humanities and from 2008 on as well by the Swiss Academy of Humanities and Social Sciences. The project will be run from 2020 at the University of Bern as part of the larger project Repertorium Academicum (REPAC), which is led by Christian Hesse and Kaspar Gubler and advised by Rainer Schwinges.
Kaspar Gubler (University of Bern) In 2017, the RAG research project found itself in a difficult situation. The database that the RAG had been working with for years was technically so outdated that an update of this software was no longer possible. Furthermore, with this software it had become more and more difficult for the RAG to publish the research data on the internet, because the data first had to be exported from the SQL-Server and imported into a web application, which was very time-consuming and error-prone. Therefore a new software for the RAG had to be evaluated in a timely manner. A colleague at the University of Bern, who had attended a nodegoat workshop, drew my attention to nodegoat. It was immediately clear to me that nodegoat fulfilled exactly the functions we urgently needed for the RAG's research data, namely data management and data visualization in one and the same software.
We invited LAB1100 to our office in Bern to discuss the data import in nodegoat. Before the meeting, LAB1100 had analysed the RAG data model and made some decisive suggestions at the meeting on how we could simplify the data model and make it easier to understand. The database migration was started in September 2017. First, the data was exported from the Microsoft SQL database, then cleaned, sorted and partially reordered in various programming steps. The final import into nodegoat was done with Python via the nodegoat JSON-API. By the end of 2017 the database migration was completed and the RAG teams at the universities of Bern and Giessen were able to enter and visualize research data in nodegoat in January 2018.
The biggest advantage of nodegoat for us is the acceleration of the work process. We now need a fraction of the time compared to the previous database to enter, analyze and publish research data. In addition, with the automated data checks of nodegoat we have data consistency under control, which is very important given the large dataset of the RAG.
Project Website: rag-online.org
Public User Interface: database.rag-online.org/viewer