How to store uncertain data in nodegoat: ambiguous identities
CORE AdminThis blog post is part of a series on storing uncertain datat in nodegoat: 'How to store uncertain data in nodegoat', 'Incomplete source material', 'Conflicting information', 'Ambiguous identities'.
There are many entities that share a name. This is often the case for cities (e.g. Springfield), or people (e.g. Francis Bacon). When you encounter such a name in a source, the context usually provides you with enough clues to know which of the entities is meant. However, in some cases the context is too vague or the entities too similar to be certain. In these cases you need to resort to interpretation and disambiguation. This is genuine scholarly work, since you always have to interpret your sources.
This blog post will describe a case in which disambiguation is needed. We will use the example of a research process that aims to reconstruct scholarly networks in the 17th and 18th century. In a research process that deals with scholarly networks, the source material will largely consist of citations and mentions in documents.
The disambiguation process will be described by means of a snippet taken from a publication by an anonymous author in 1714 with the title 'An account of the Samaritans; in a letter to J---- M------, Esq;' (ESTC Citation No. N16222).
This blog post uses the data model that was created in the nodegoat guide 'Create your first Type', and will use elements from the guide 'Add External Identifiers', and from the guide 'Add Source References'.
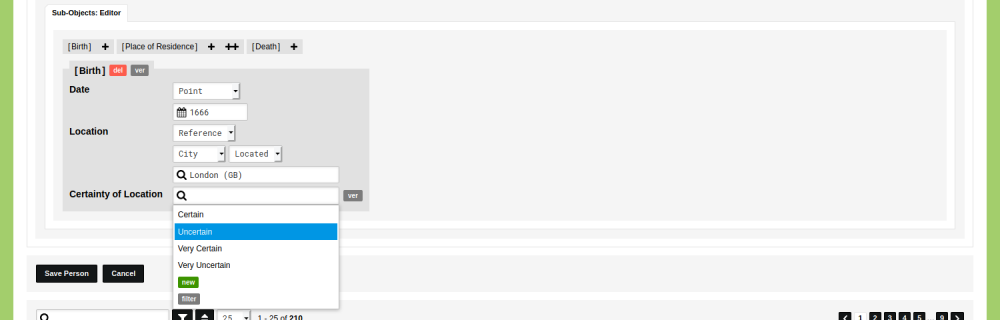
To store 'mentioned' statements, you can use the Type that was created in the guide 'Add Source References' and add a new Sub-Object in which mentions can be saved. To change the model, go to Model and edit the Type 'Publication'. Switch to the tab 'Sub-Object' and create a new Sub-Object with the name 'Mention'. Set the Date to 'None' and Location to 'None'. In the tab 'Description', click the green 'add' button twice to create three Sub-Object Descriptions. Name the first 'Person', the second 'Page Number', and the third 'Notes'. Set the value type for 'Person' to 'Reference: Type' and select the Type 'Person'. Set the value type for 'Page Number' to 'Integer' and set the value type for 'Notes' to 'Text'.
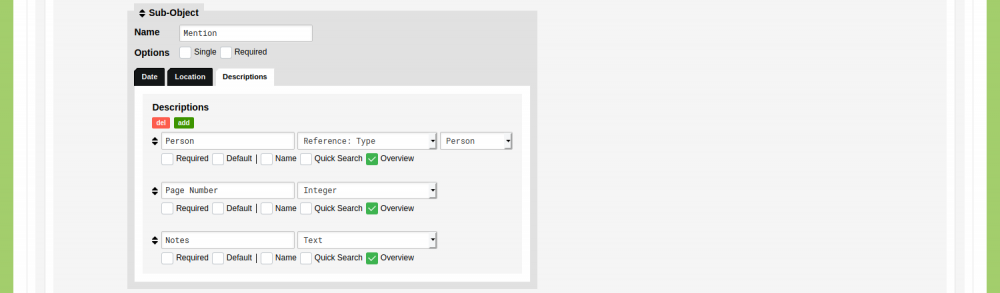
These settings are not set in stone. Adjust them so that they work for your project.[....]